FlashAttention
参考:北京大学机器学习研究中心 Kun Yuan 课程讲义 FlashAttention(22_FlashAttention.pdf),以及讲义中引用的 FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness。
本文目标:完整梳理 FlashAttention 的动机、核心公式、Kernel Fusion 与 Online Softmax、块化算法流程、复杂度分析和实验结论,并与标准注意力实现做逐点对比。
1 问题背景:Attention 的瓶颈不只在 FLOPs¶

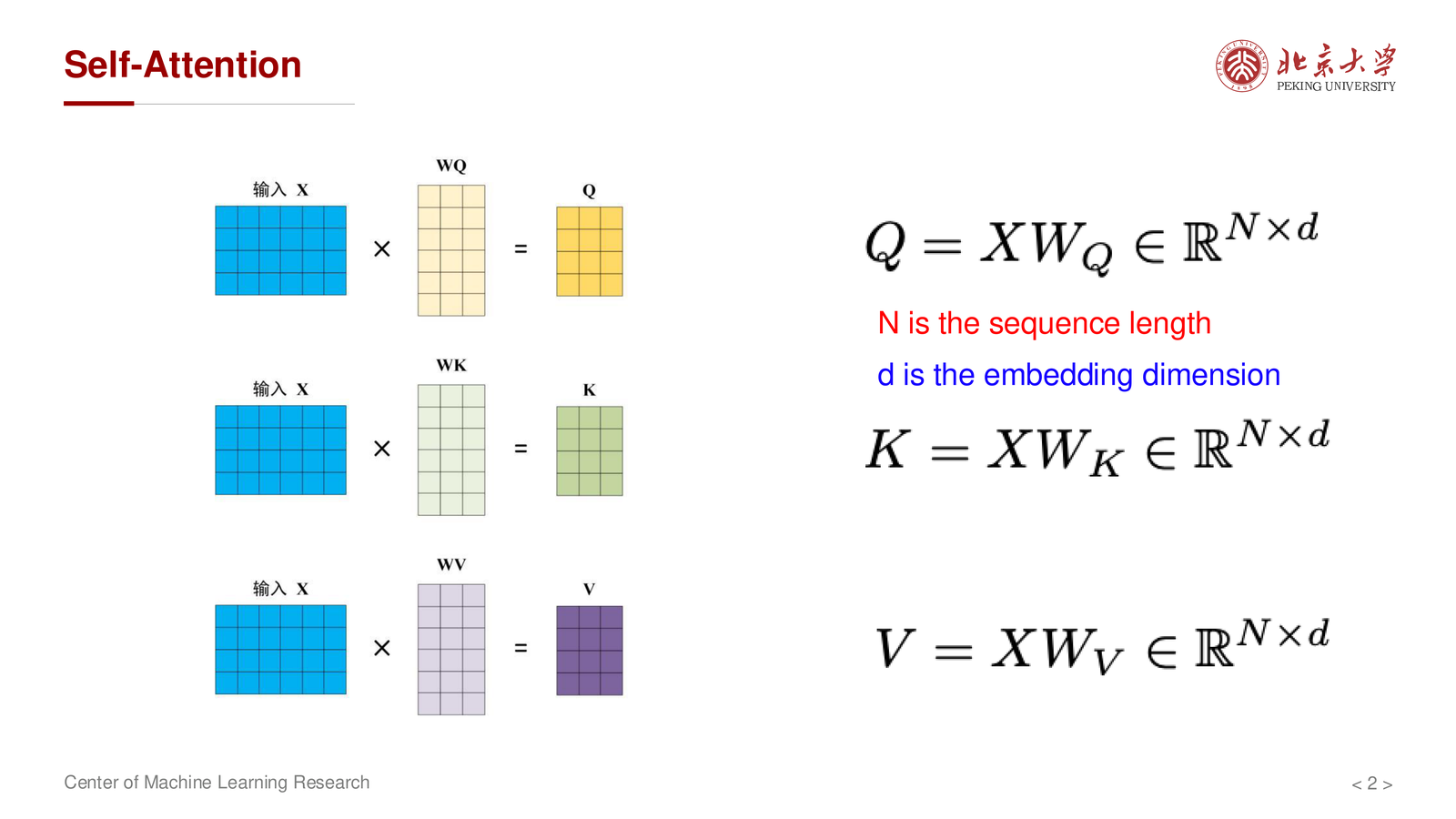
标准自注意力:
其中 \(Q, K, V \in \mathbb{R}^{N \times d}\),\(N\) 是序列长度,\(d\) 是 embedding 维度。
从计算量看,自注意力是 \(O(N^2 d)\),这是大家熟悉的二次复杂度结论。
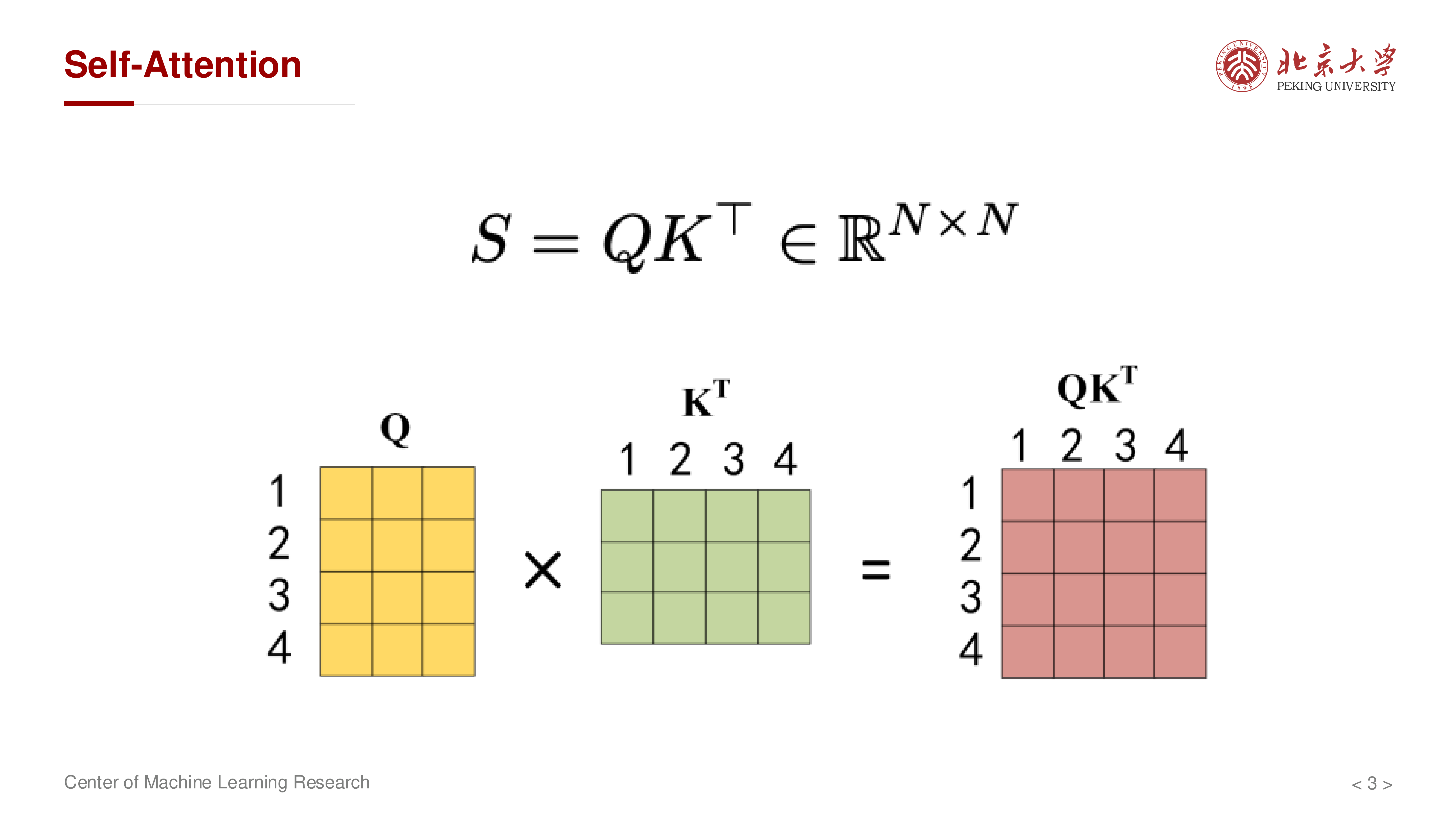
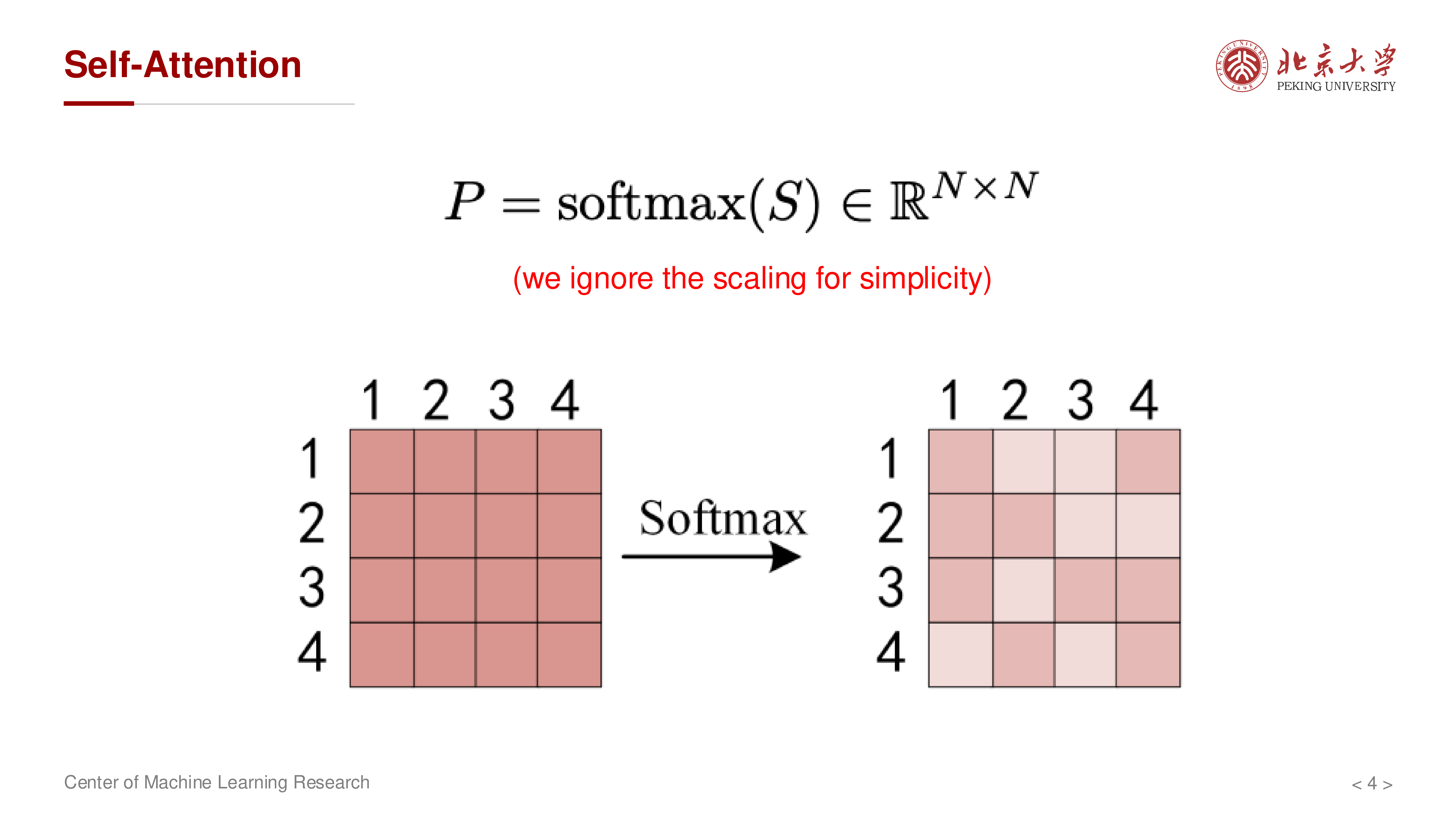
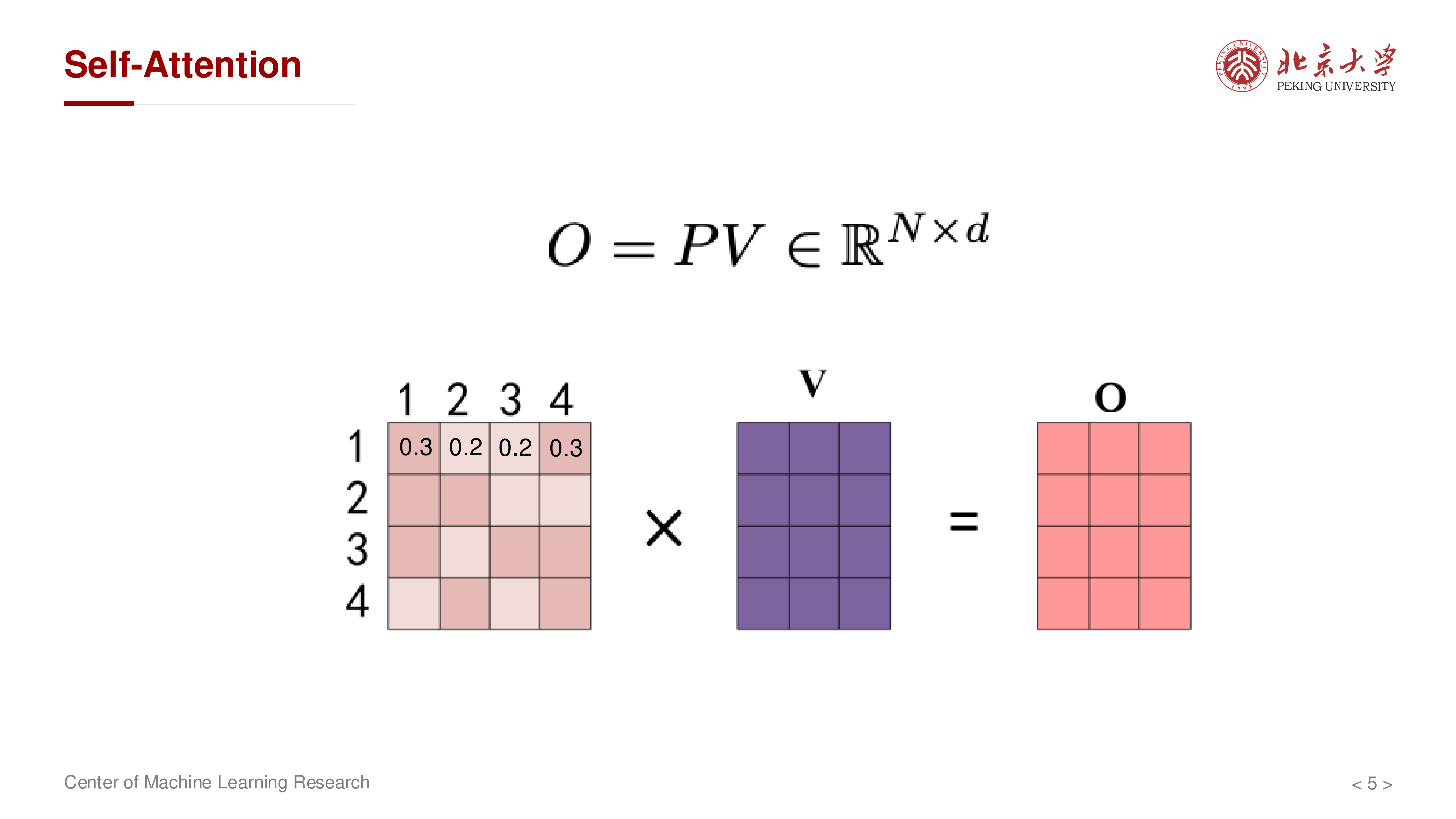
仅降 FLOPs 往往不够
讲义强调:许多方法把理论复杂度从 \(O(N^2)\) 降到 \(O(N)\),但实际加速并不显著,关键原因是它们没有有效降低 Memory Access Cost(MAC)。
2 IO 视角:GPU 上真正慢的是 HBM 访问¶

GPU 执行模型(简化)可理解为:
- 从 HBM(大但慢)读入数据到 SRAM(小但快)
- 在 SRAM / 寄存器中计算
- 再把结果写回 HBM

在 Transformer 中,矩阵乘通常是 compute-bound,而大量逐元素/归约算子是 memory-bound。注意力实现中如果频繁读写中间矩阵(尤其是 \(N \times N\)),会被 HBM 带宽限制。

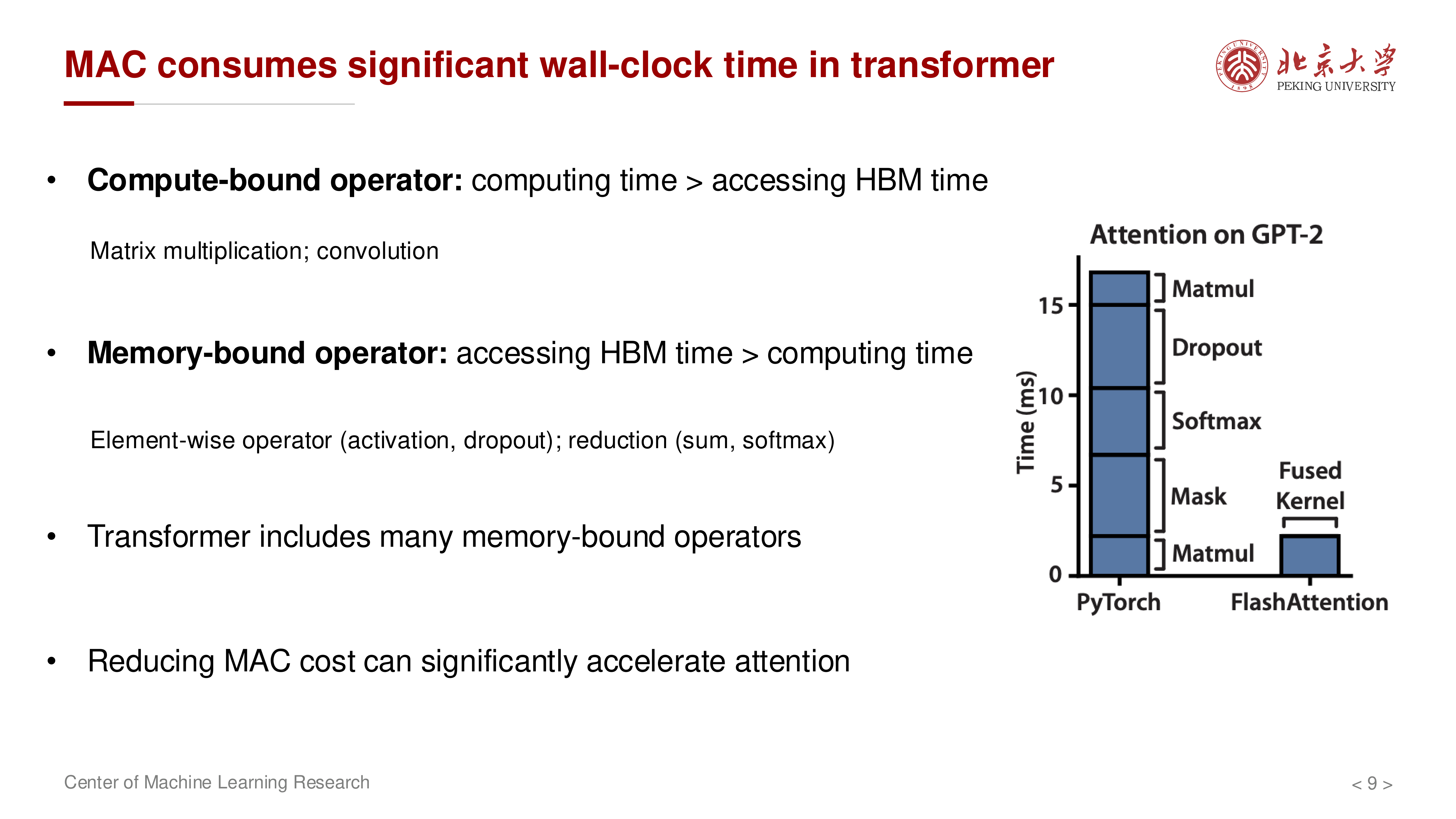
标准实现常见访问开销(按讲义口径):
二次项来自对中间 \(S, P\) 的写回与再读取。
3 FlashAttention 的第一性原理:Kernel Fusion¶

核心思想是把本来分离的算子融合成更大的 kernel,避免中间结果落到 HBM。
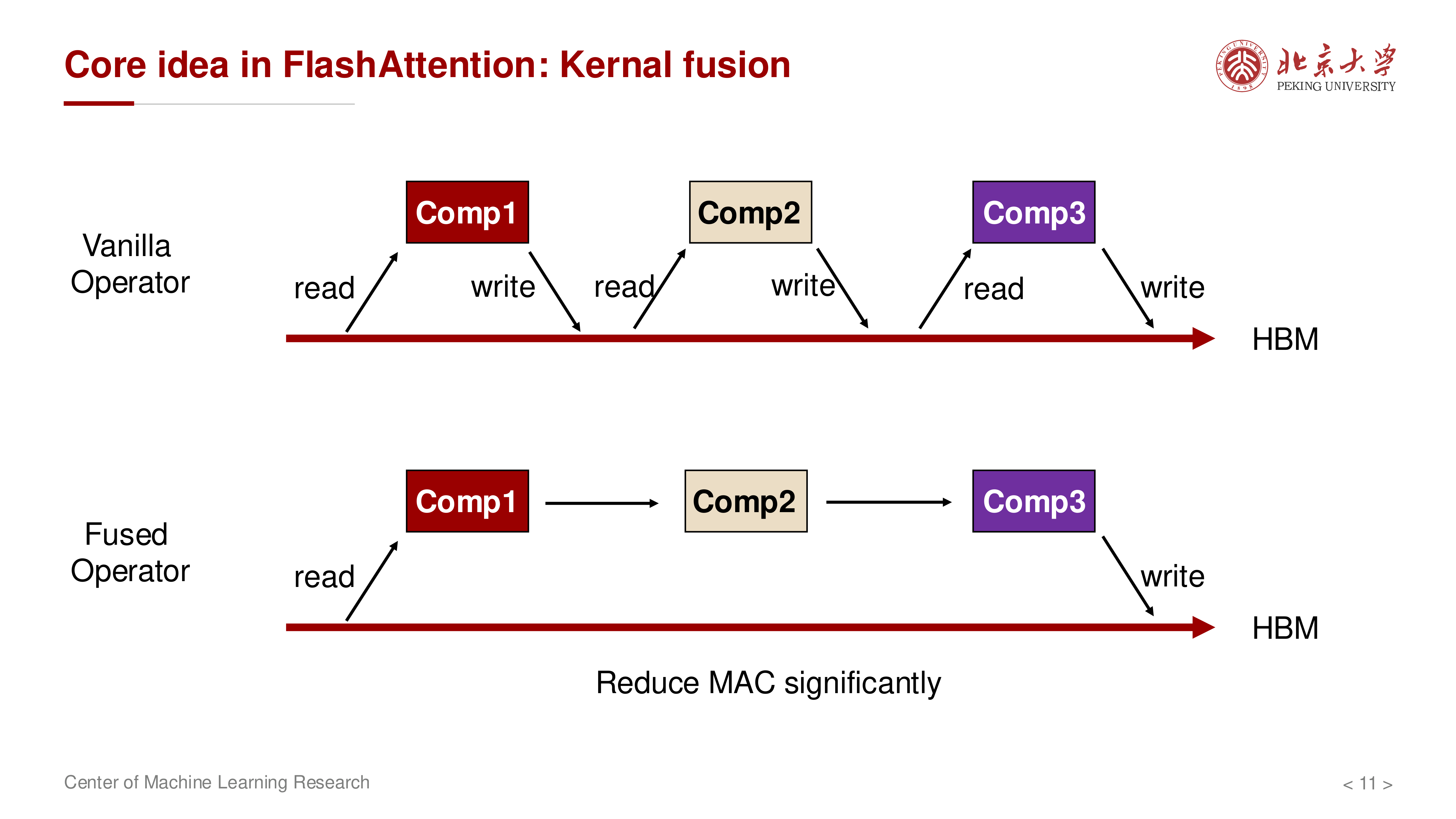
Kernel Fusion(内核融合)
不是改变注意力数学定义,而是改变执行计划:在片上内存中尽量完成 QK^T -> softmax -> 与 V 相乘 的连续流水,减少 HBM 往返。
4 从无 Softmax 的简化版开始理解¶
先忽略 softmax,把注意力写成:
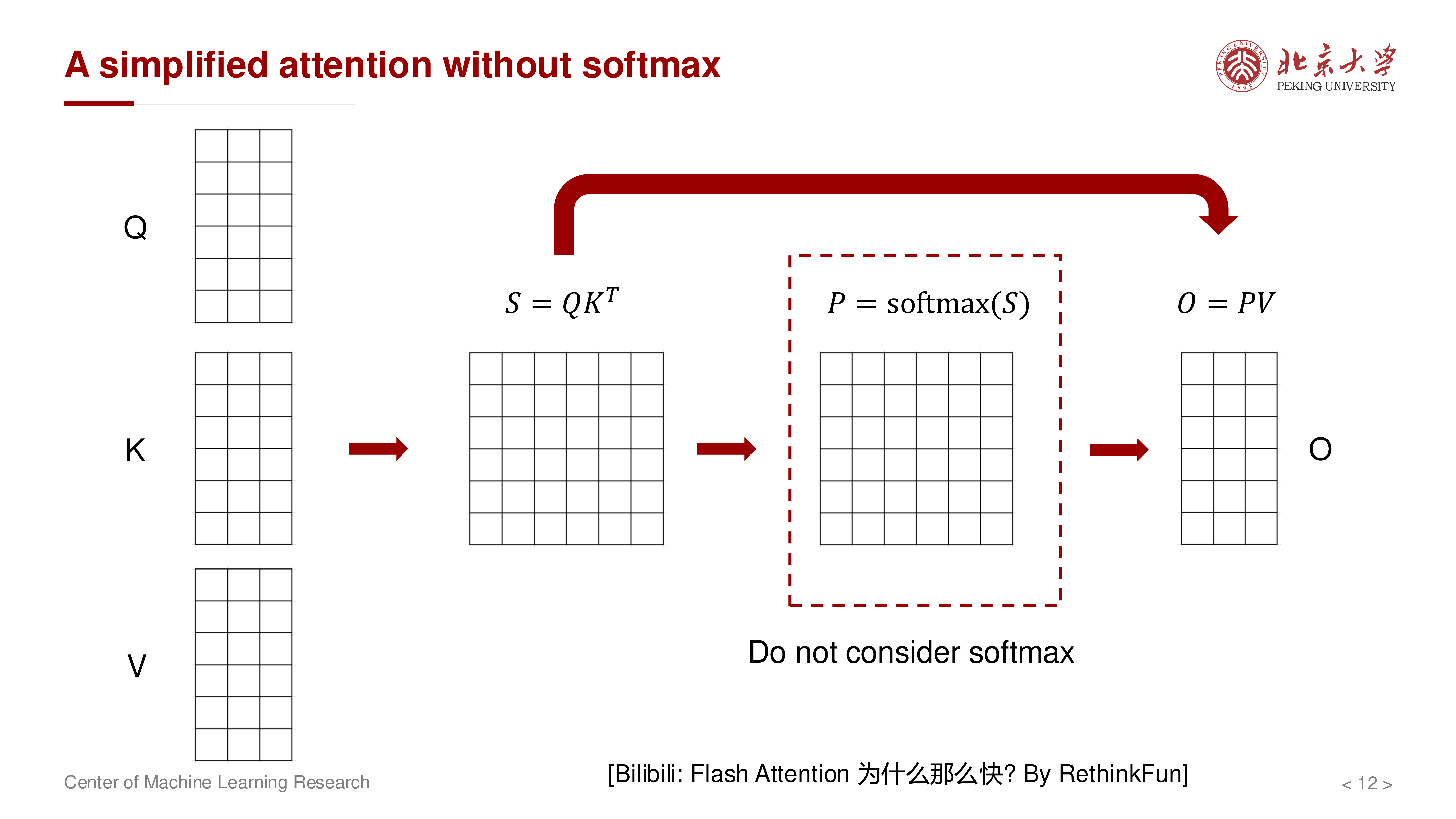
如果把 \(K^\top, V\) 分块并在 SRAM 中处理,就可以把多个中间步骤融合,不再写出完整的 \(S\)。
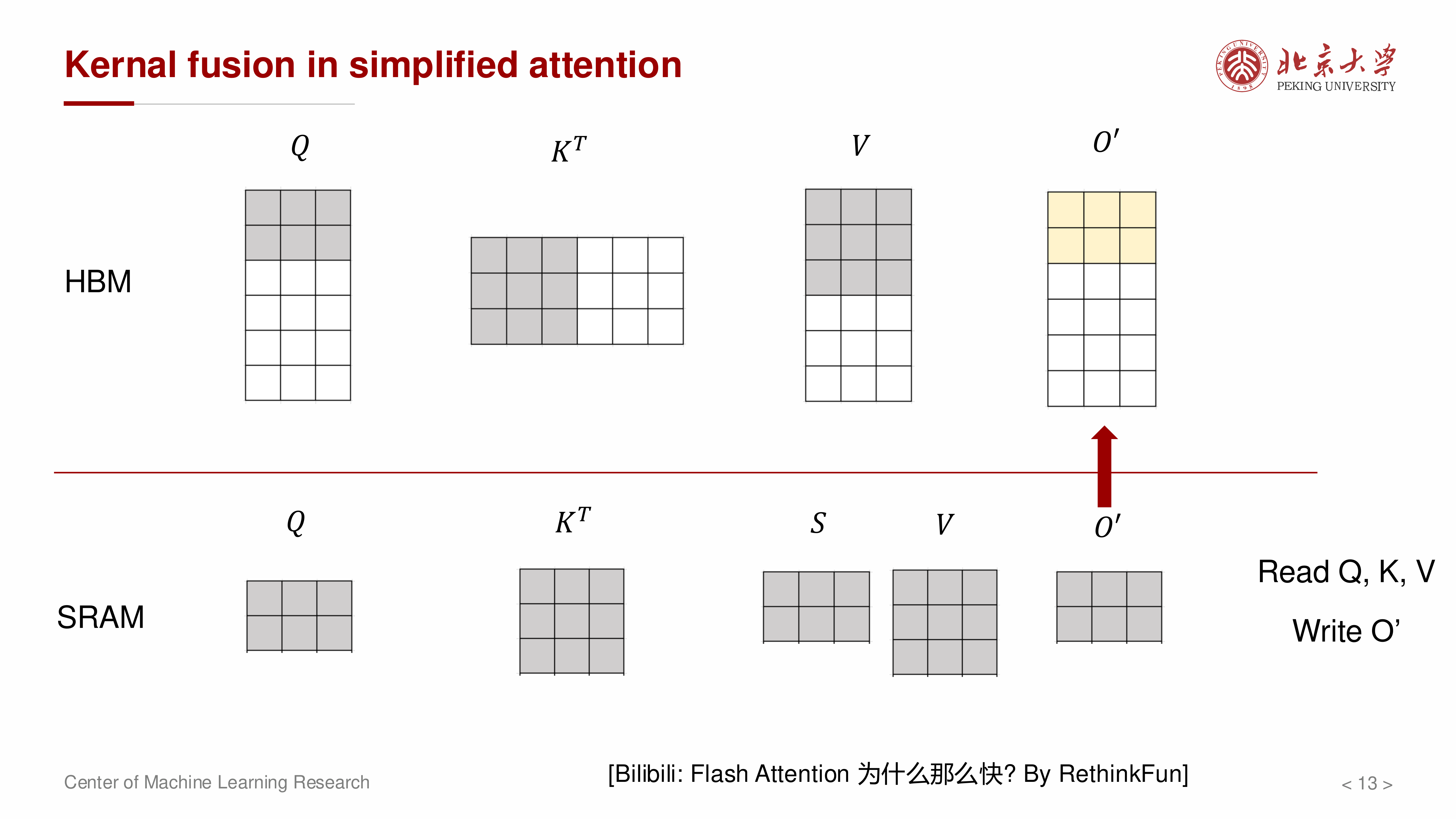
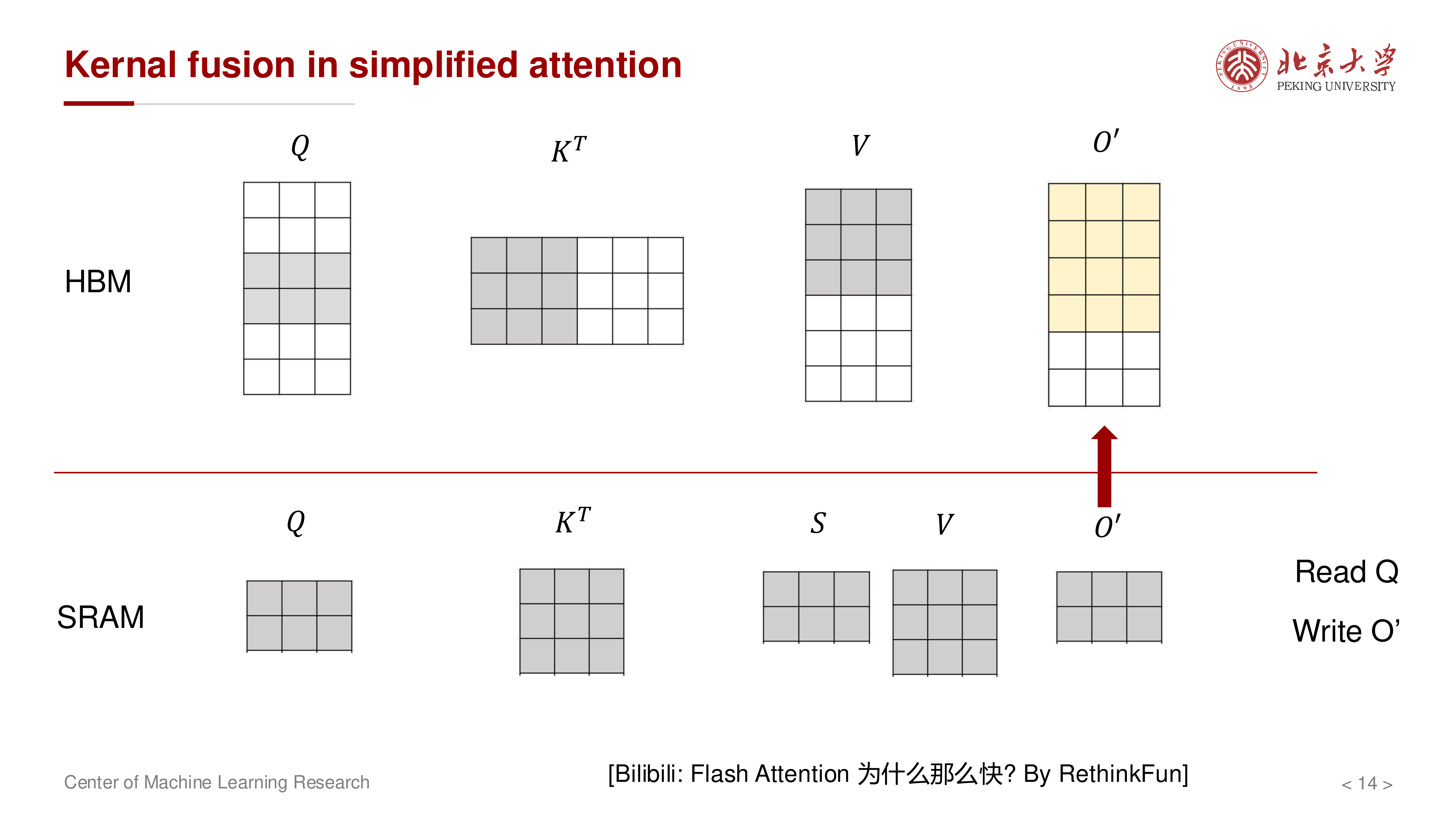
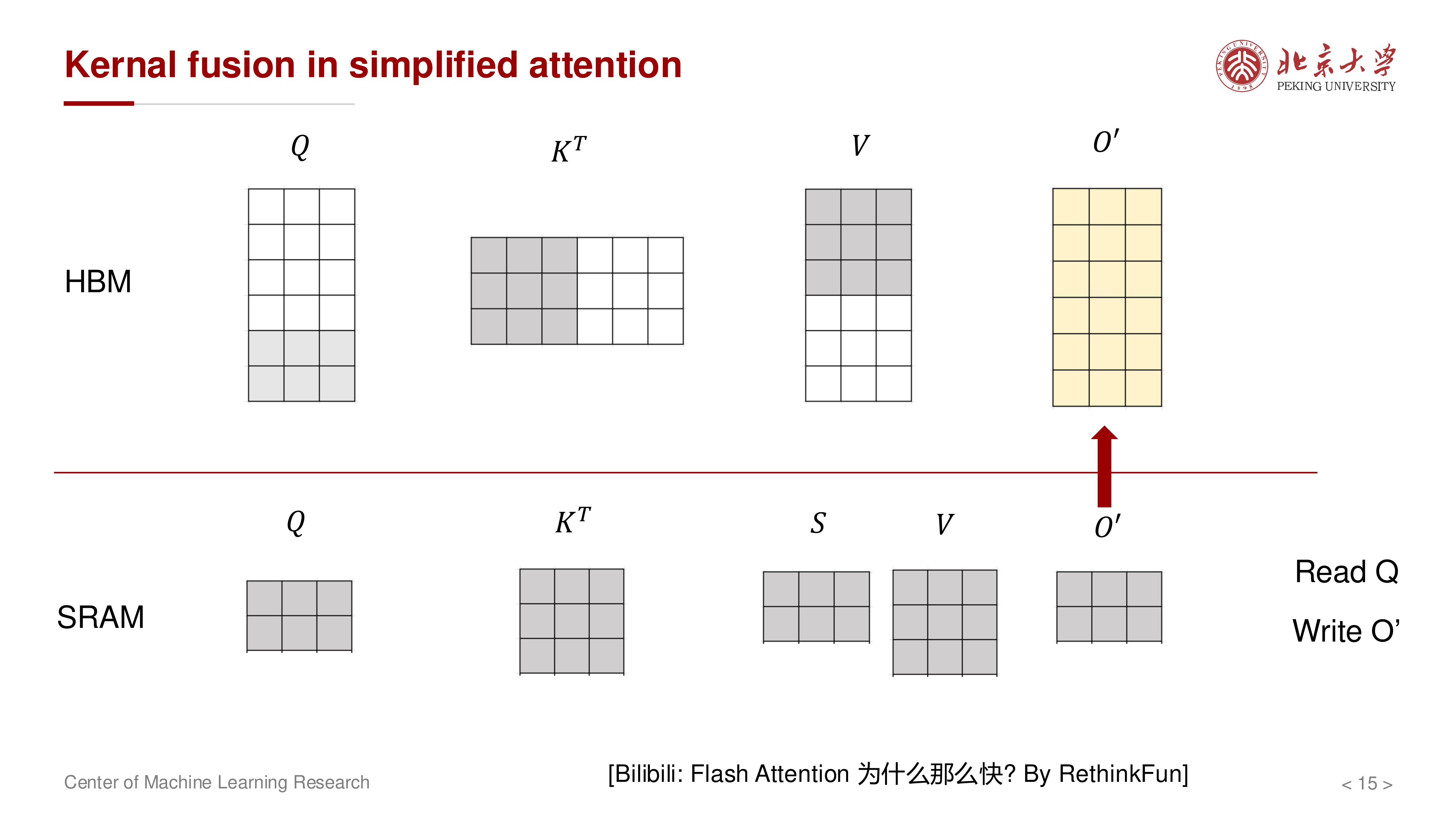
当输出按块累加时,只需维护部分输出块并回写:
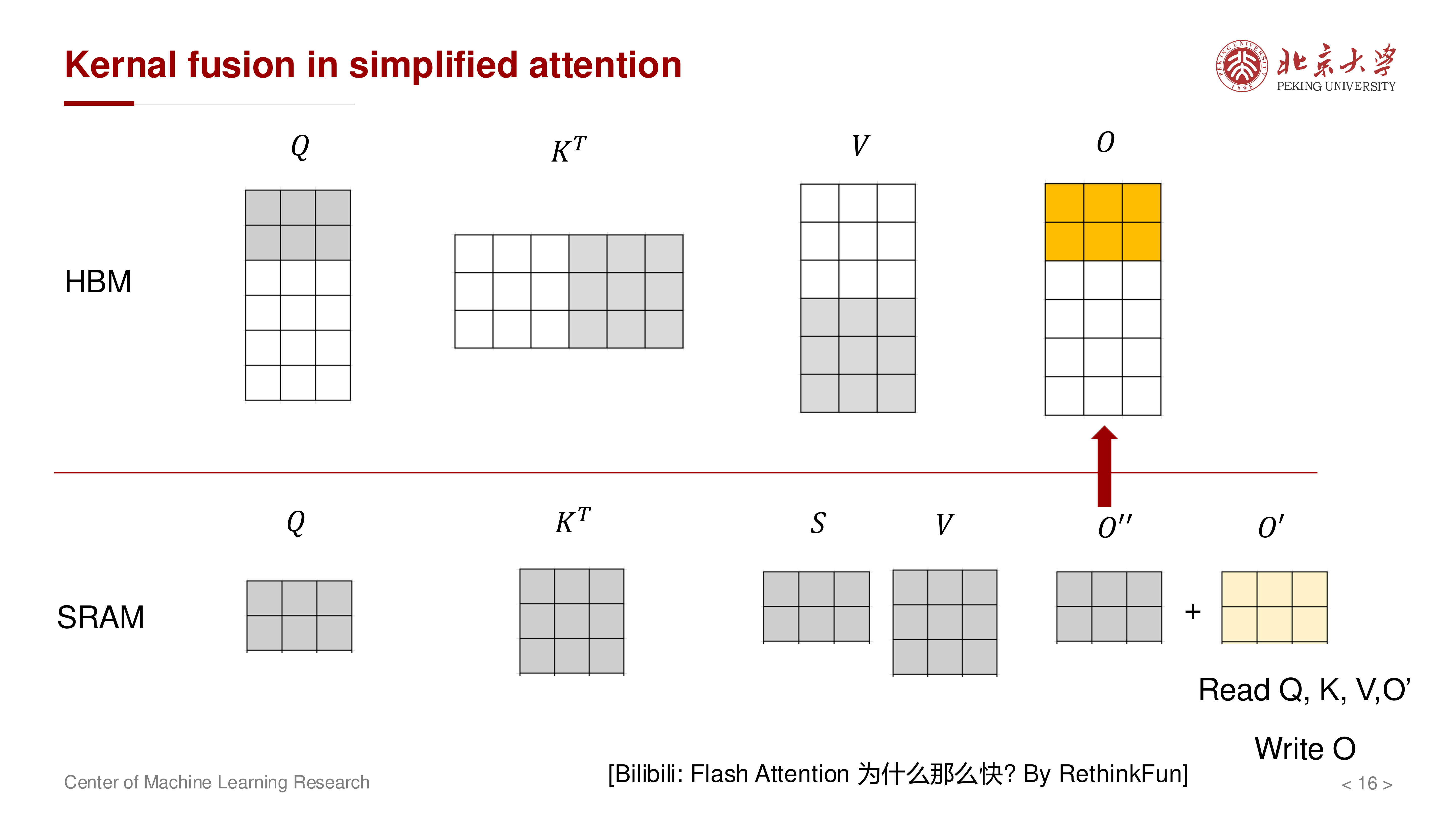
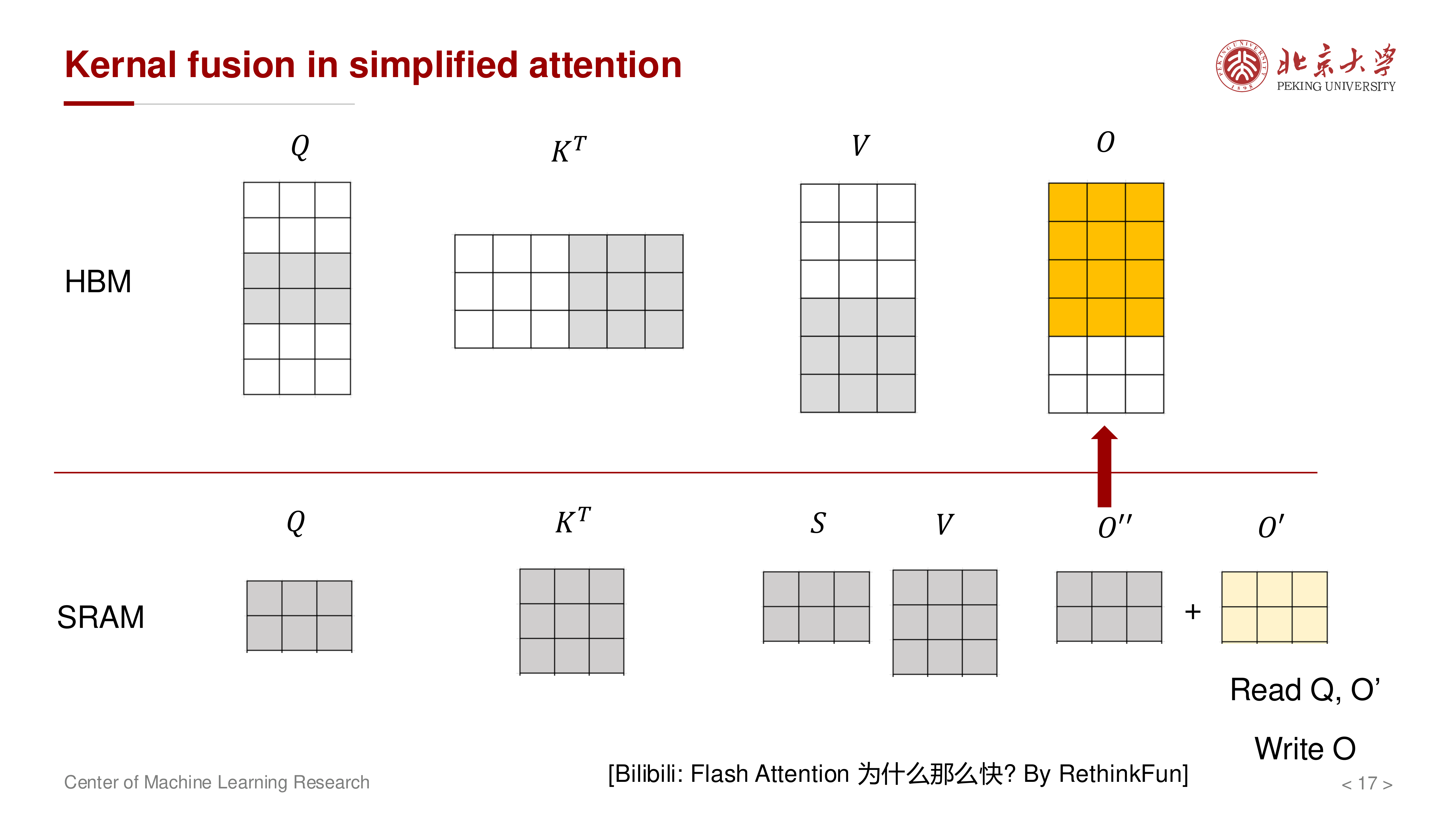
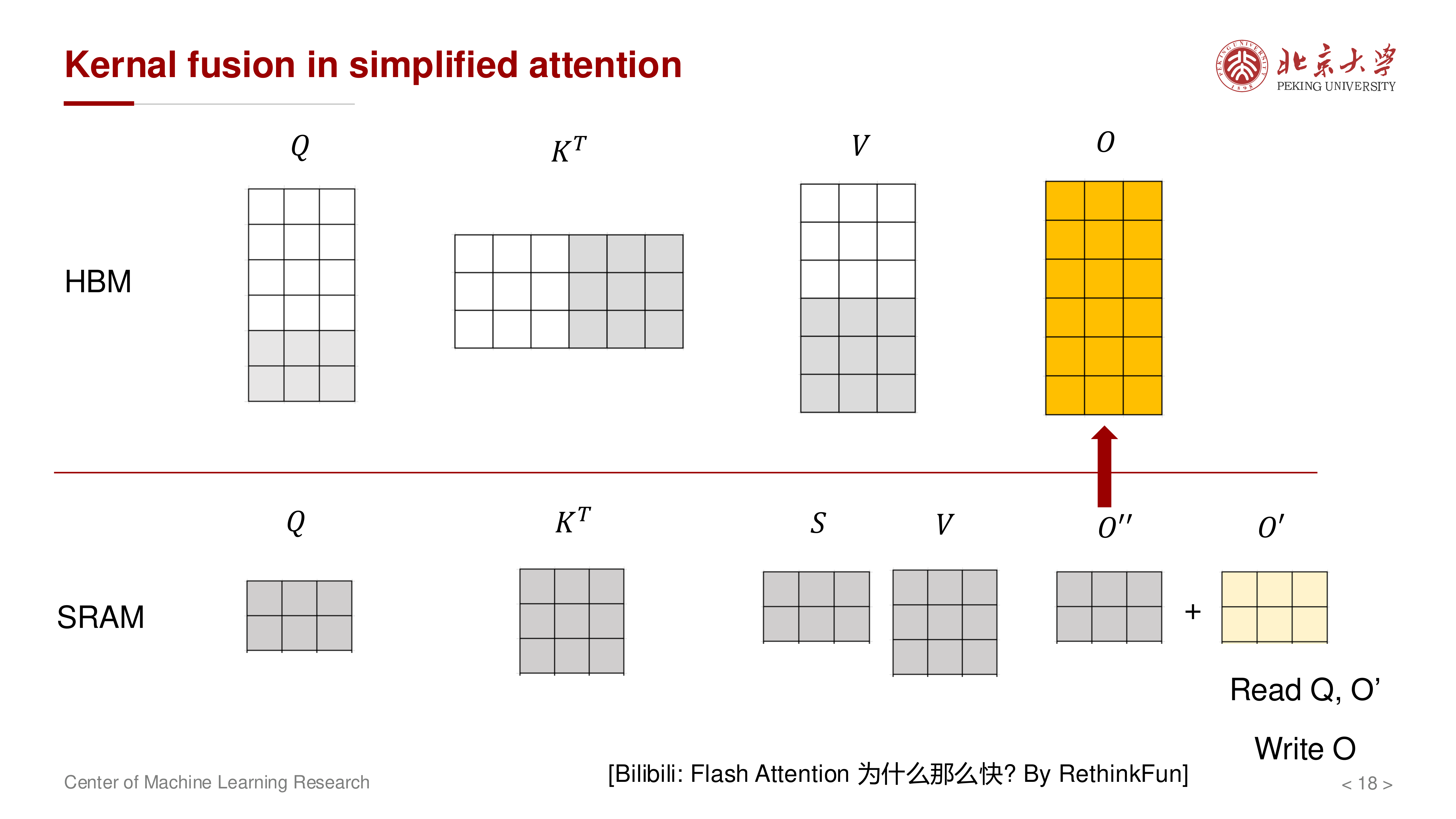
对应的 MAC 对比(讲义):

当 \(N \gg d\) 时,二次项主导,融合方案优势显著。

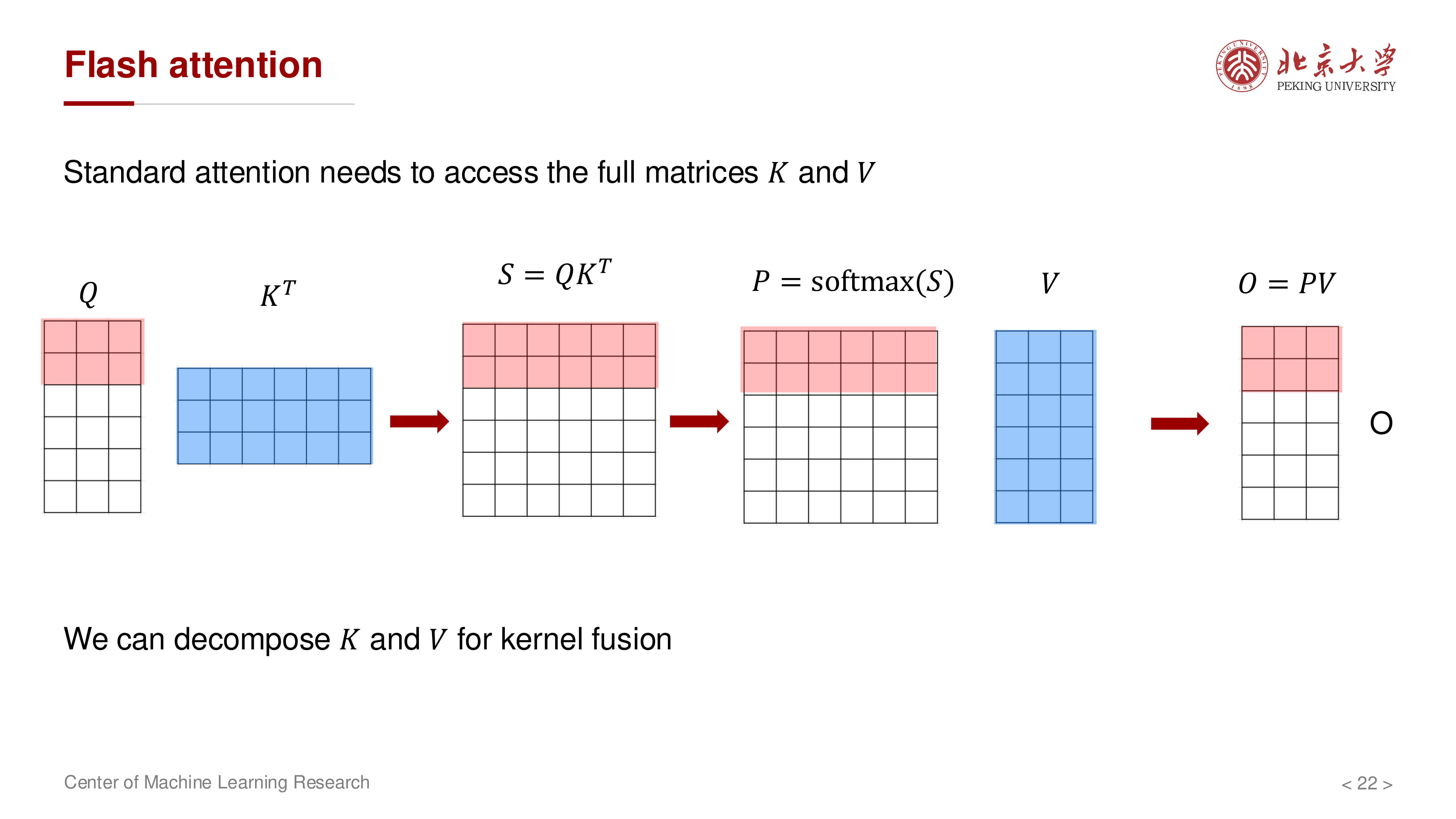
5 关键难点:如何在分块下精确处理 Softmax¶
难点在于 softmax 的分母是整行归一化,看起来需要拿到完整一行分数:
为数值稳定,通常写成:

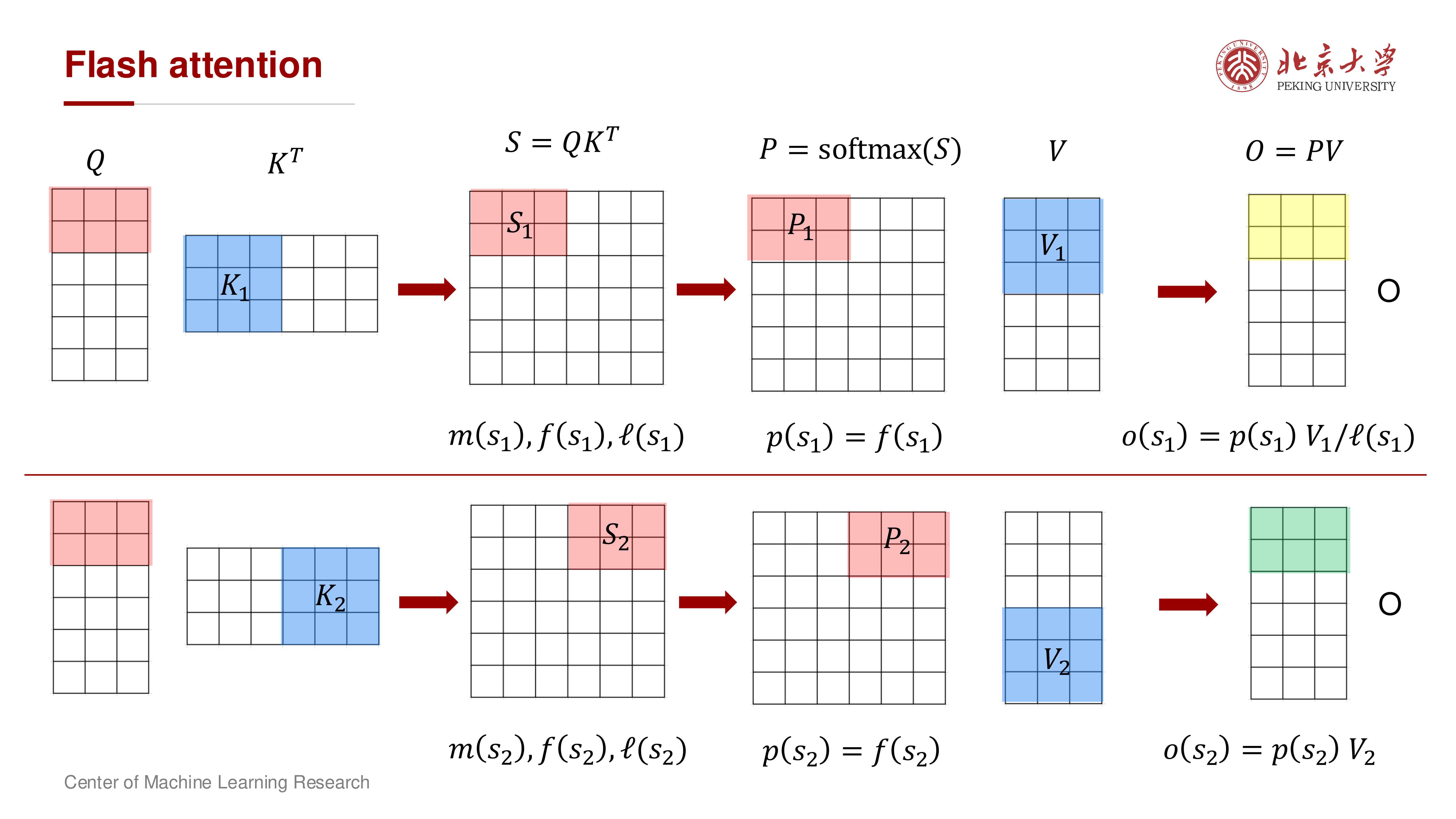
FlashAttention 使用 Online Softmax 思想:按块扫描时维护每一行的运行统计量:
- 运行最大值 \(m\)
- 运行归一化因子 \(\ell\)
- 运行输出向量 \(o\)
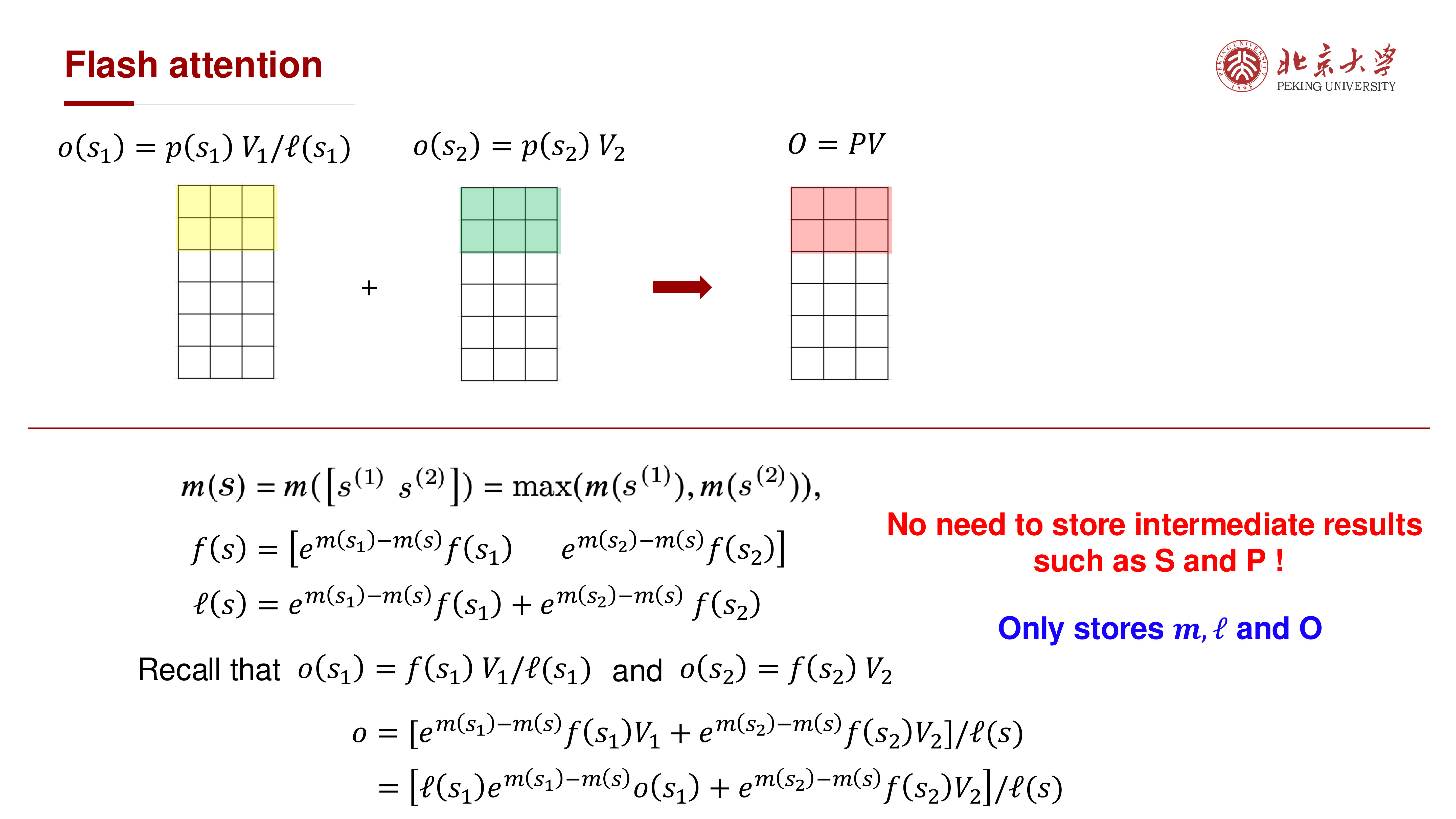
当新块到来时,利用重标定(rescaling)更新上述量,无需保存完整 \(S\) 或 \(P\)。
6 分块公式:只存 m、l、O,不存 S、P¶
先给出分块符号。设对某个 query 行(或 query block 内每一行):
- 第 \(t\) 个 key/value 块产生分数向量 \(s^{(t)} = q(K^{(t)})^\top\)
- 局部最大值 \(m^{(t)} = \max s^{(t)}\)
- 局部指数和 \(f^{(t)} = \sum_j e^{s^{(t)}_j - m^{(t)}}\)
- 局部加权和 \(u^{(t)} = \sum_j e^{s^{(t)}_j - m^{(t)}} v_j^{(t)}\)
全局运行量更新为:
这就是讲义中“只保留 \(m,\ell,O\)”的核心。
7 计算顺序优化:固定 K/V,遍历 Q¶
如果固定 \(Q\) 去遍历所有 \(K,V\),仍会带来较高 HBM 流量。讲义进一步强调应采用更 IO 友好的遍历顺序:固定一个 \(K,V\) 块,让多个 \(Q\) 块复用它。
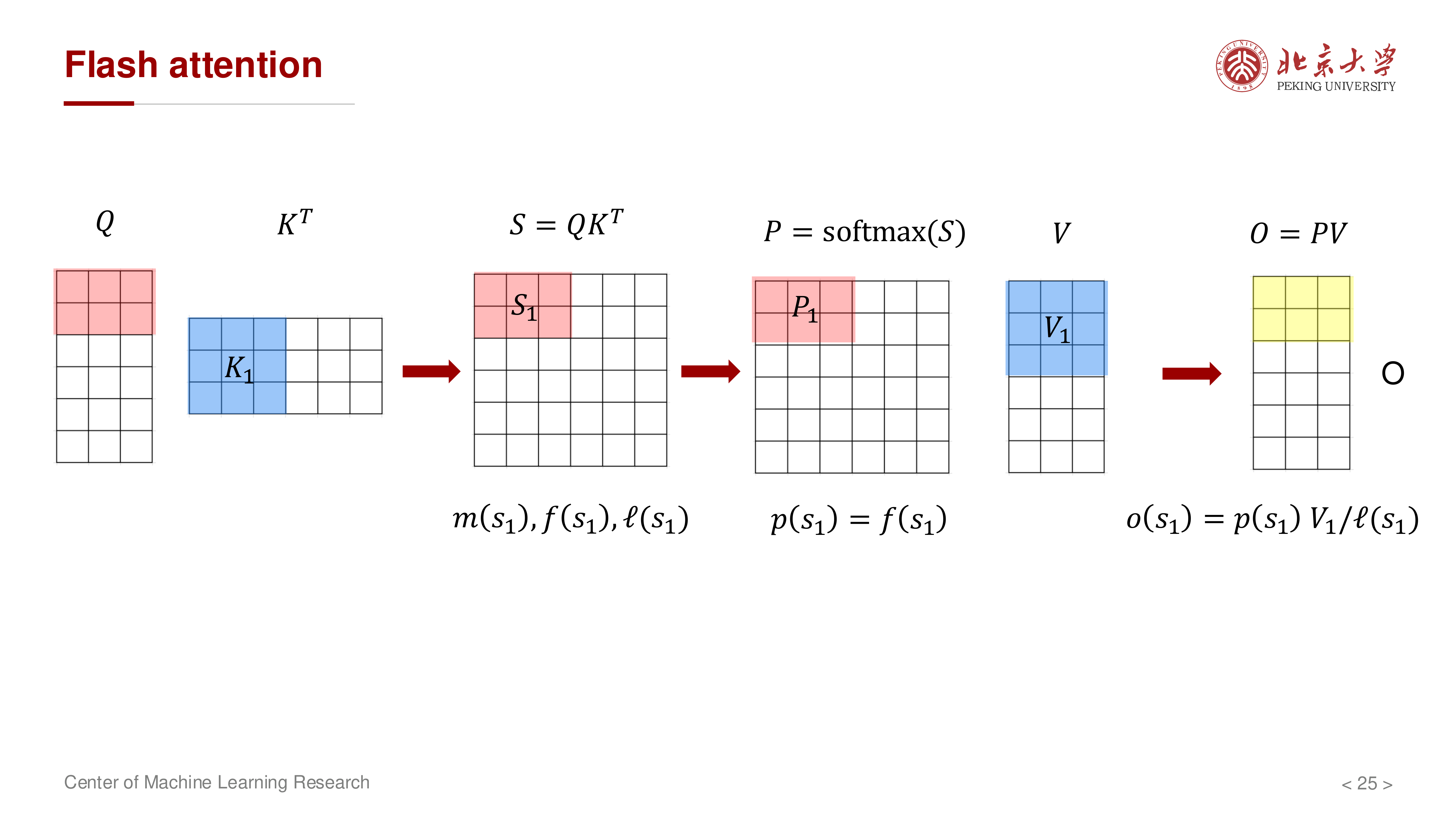
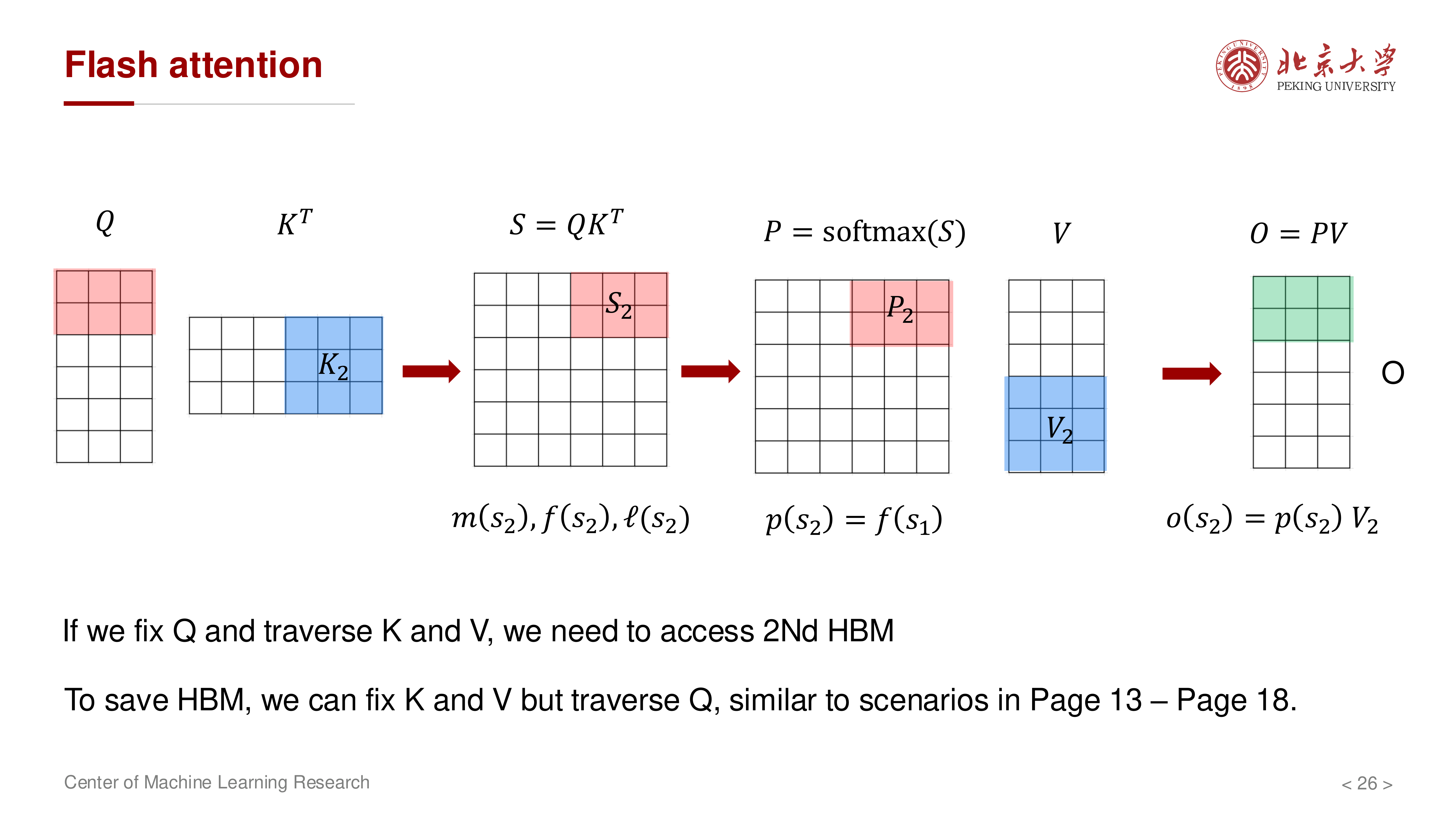
典型流程:
- 读入一个 \(K_j, V_j\) 块到 SRAM
- 依次遍历多个 \(Q_i\) 块
- 对每个 \(Q_i\) 块更新其对应的 \((m_i, \ell_i, O_i)\)
- 处理下一个 \(K_{j+1}, V_{j+1}\) 块
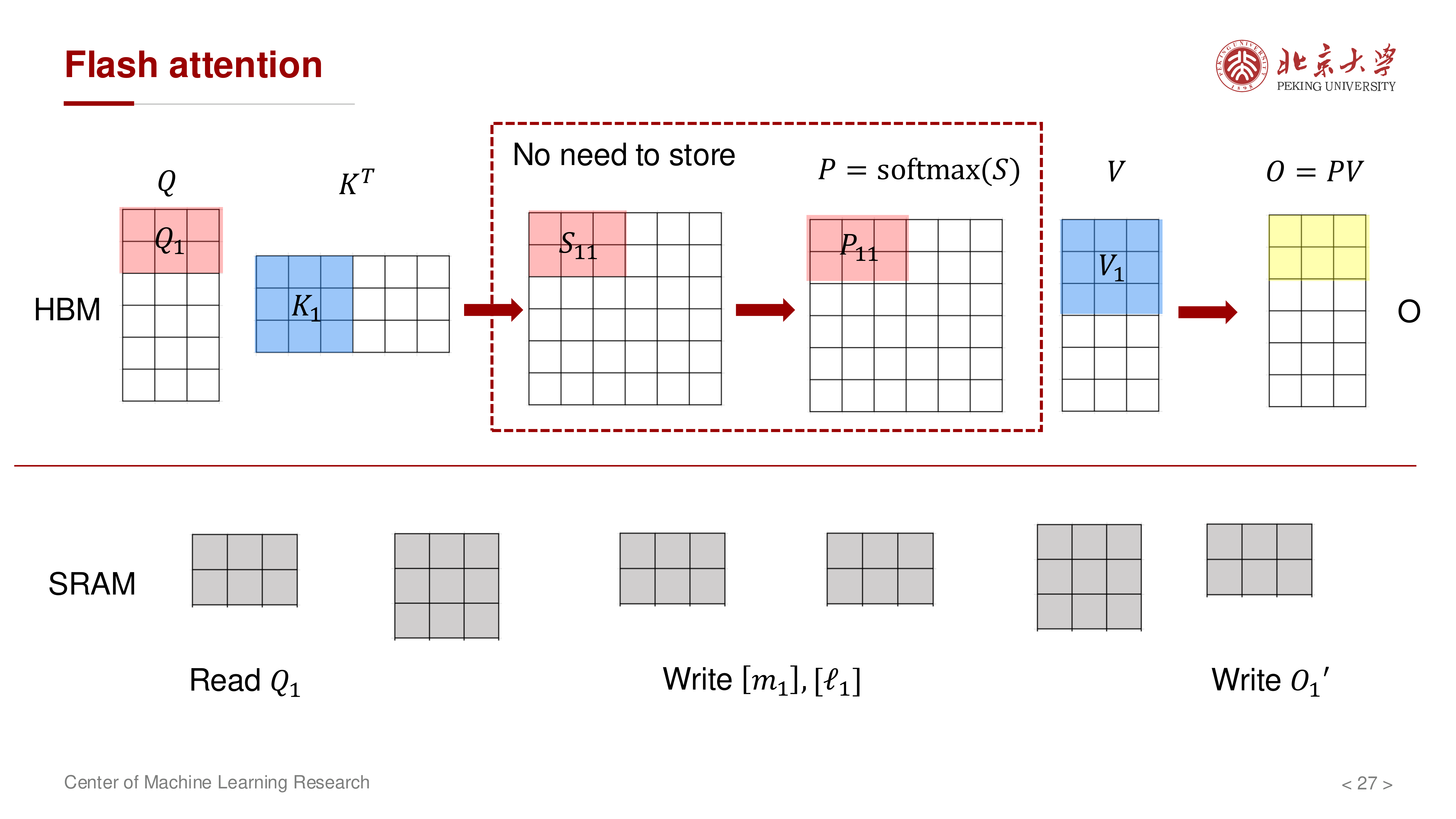
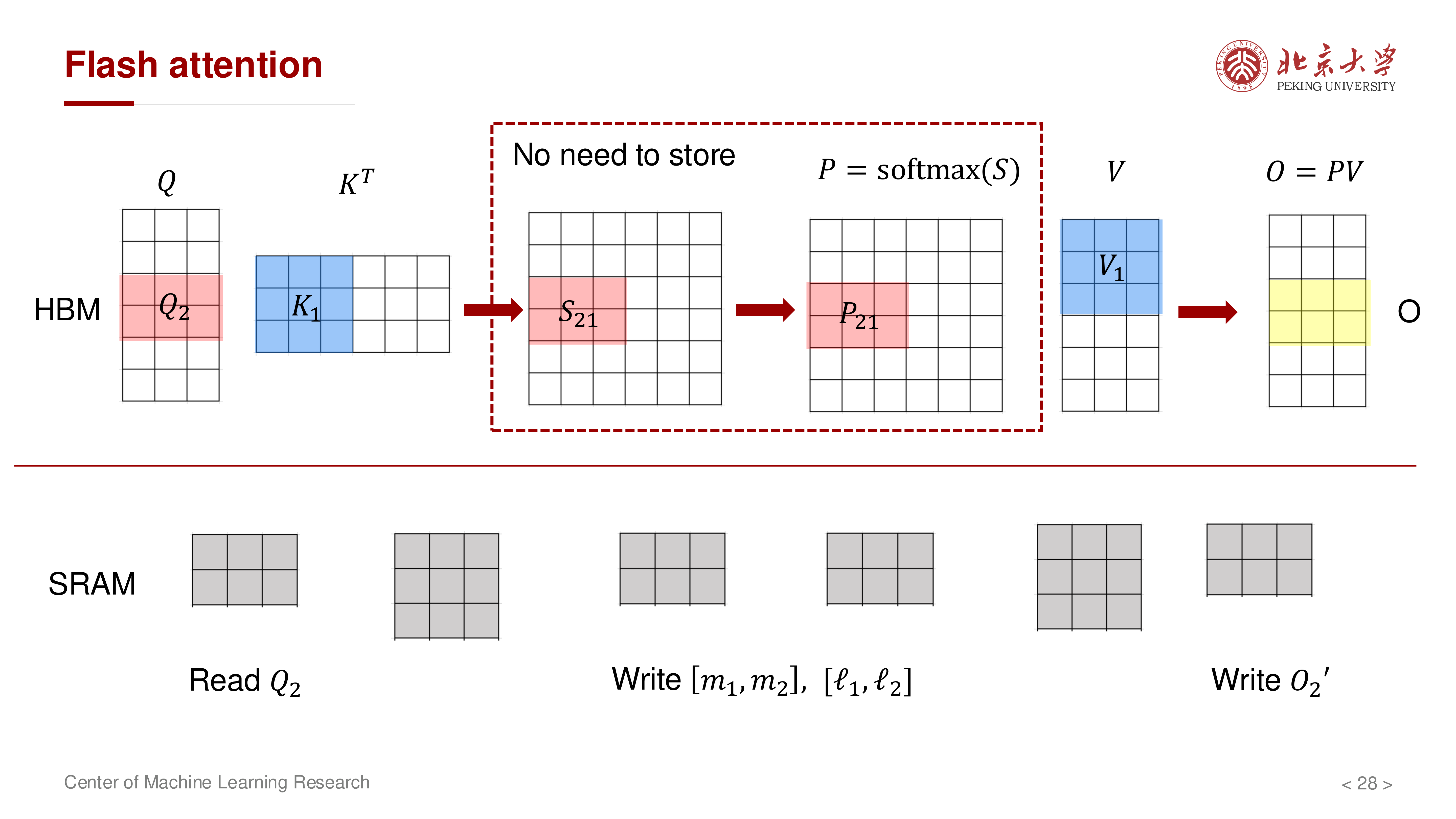
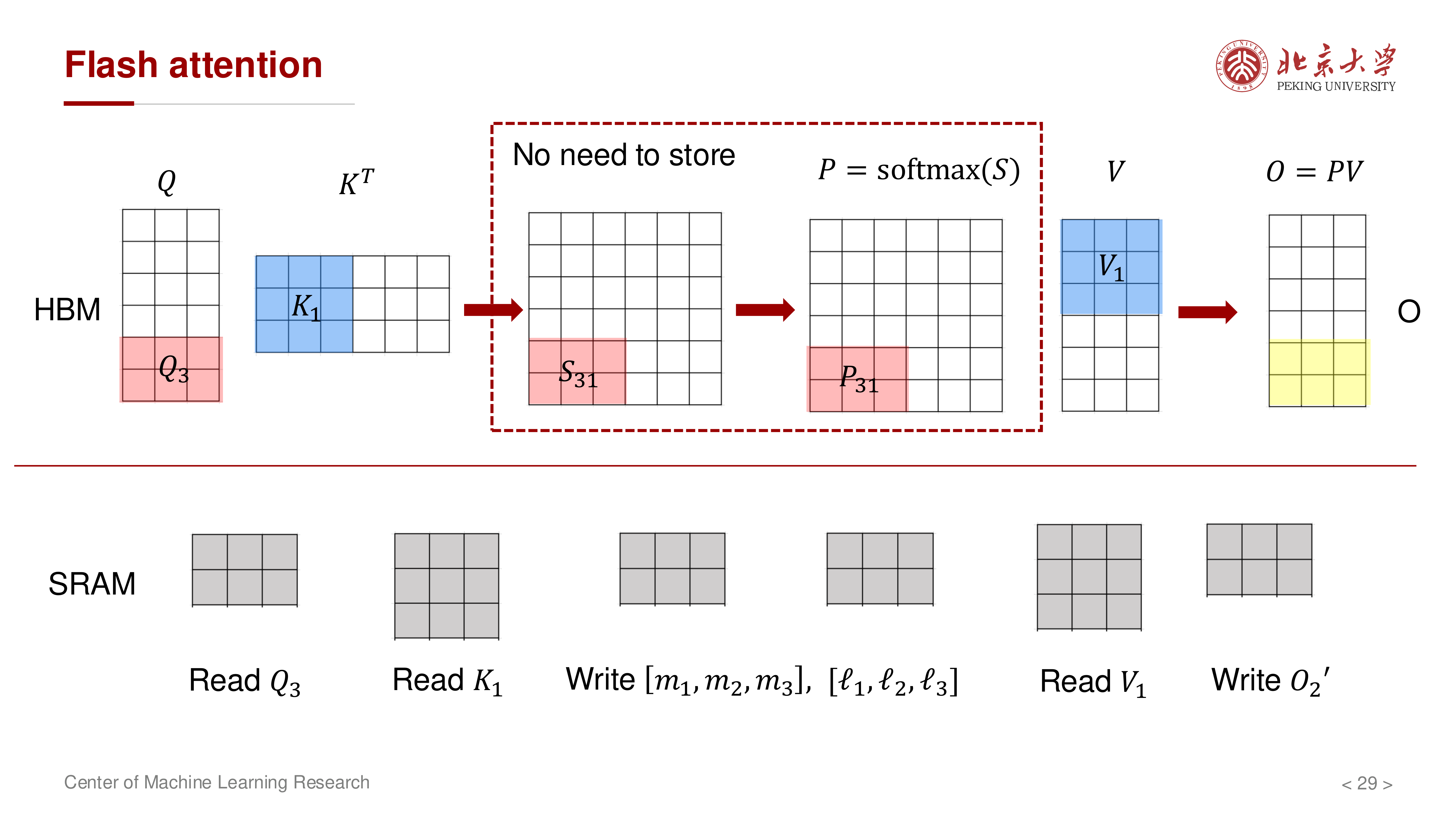
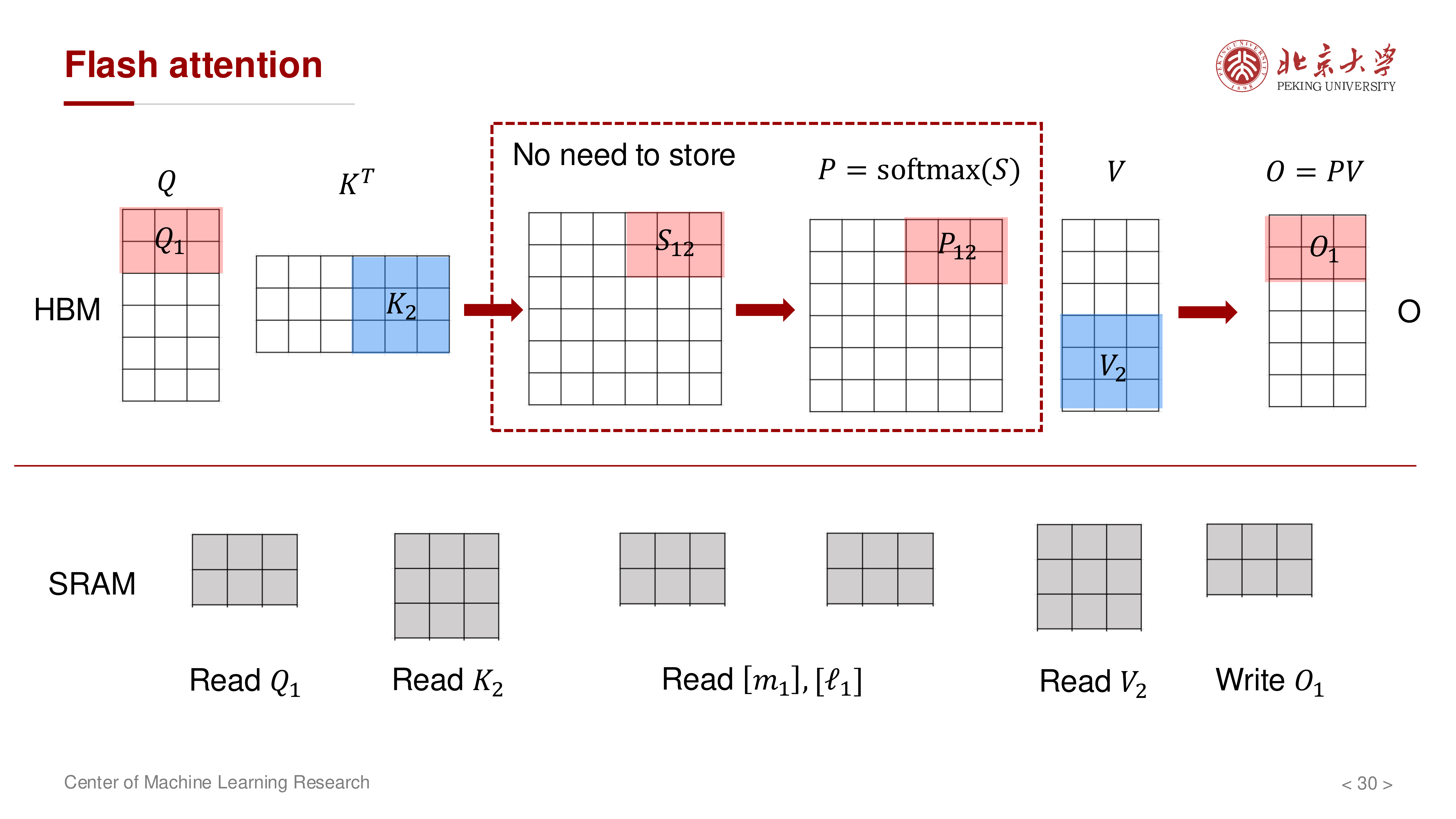
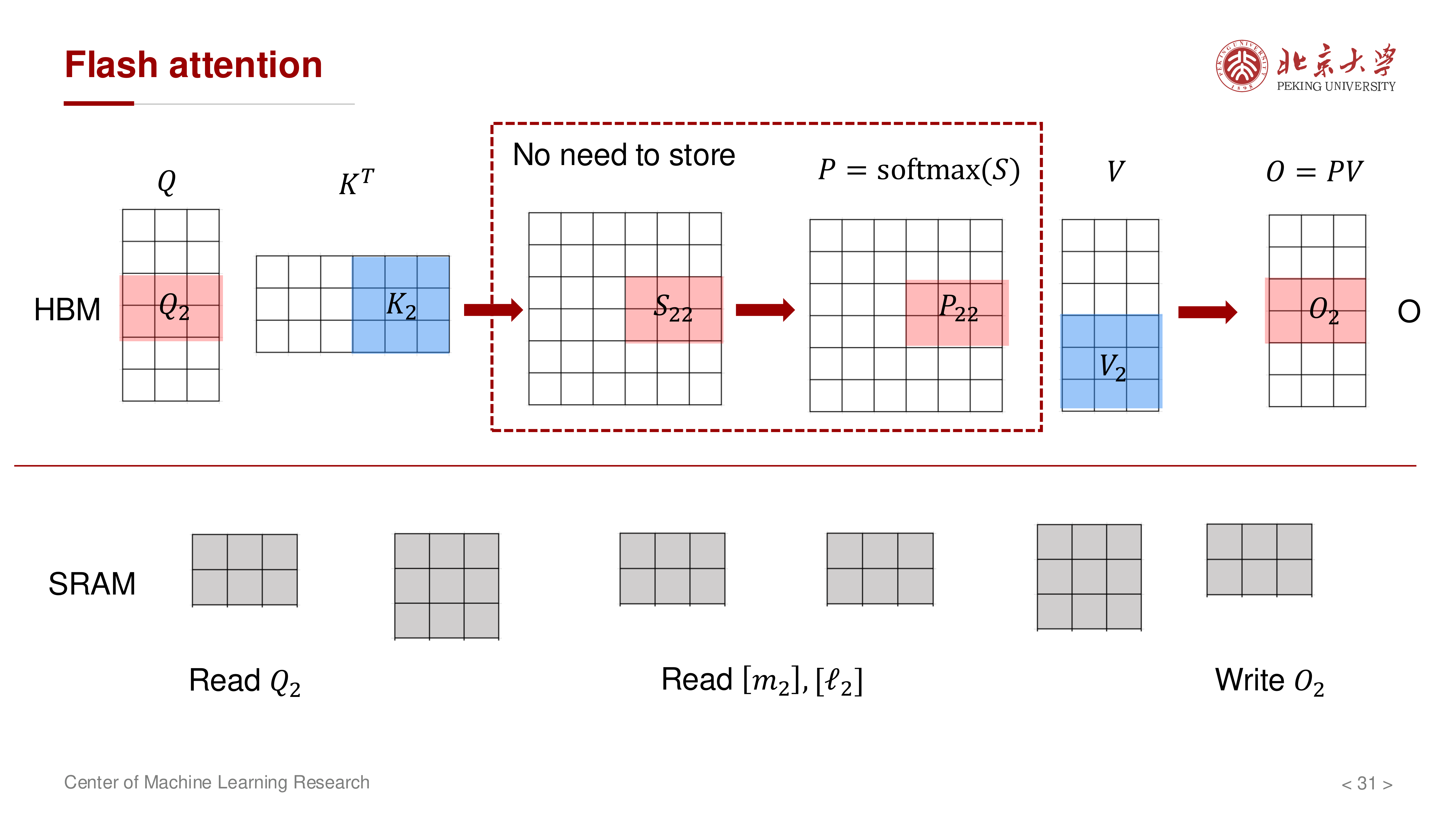
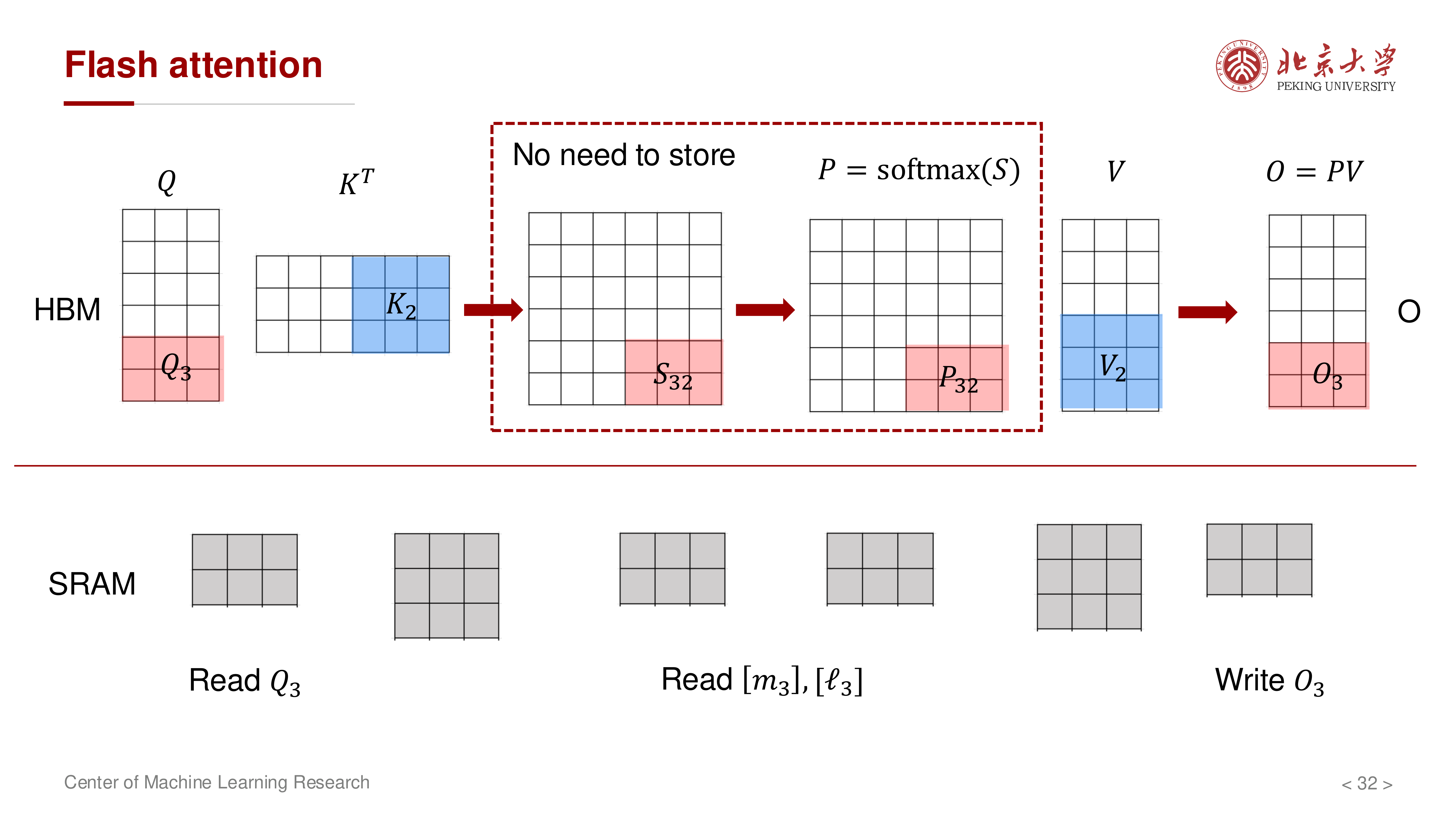
8 算法与复杂度¶
算法 8.1(FlashAttention 分块前向,IO-aware)¶
复杂度结论(讲义口径)¶
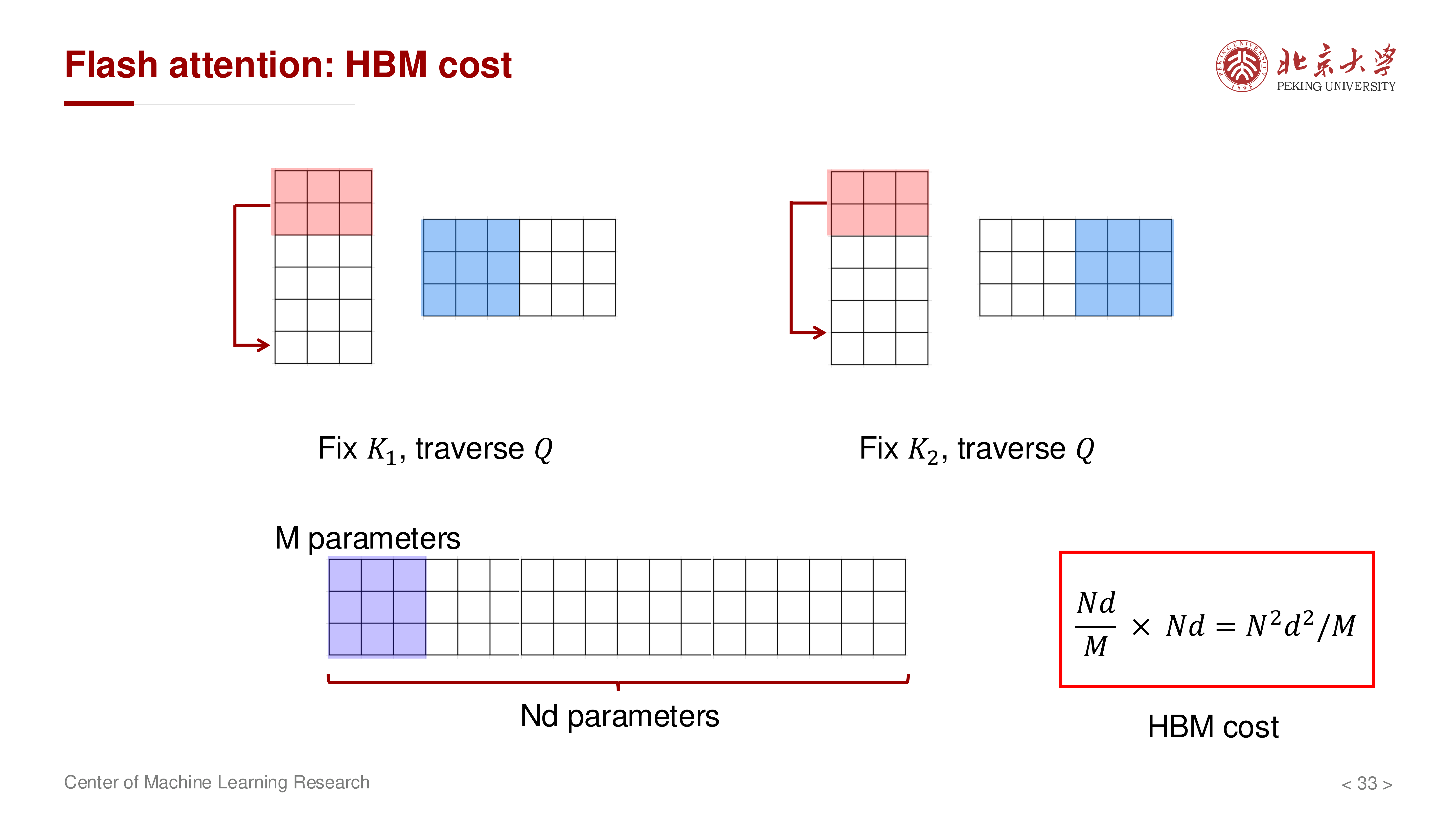

HBM 访问量近似:
其中 \(M\) 表示片上可用 SRAM 规模(按元素计)。标准注意力相关项大致是:
在常见配置中 \(M \gg d^2\)(讲义示例:\(M \approx 10^6\),\(d \in [64,128]\)),因此 FlashAttention 可显著减少 HBM 流量。
显存占用对比(是否物化中间矩阵):
工程直觉:FlashAttention 的关键收益不是改写数学定义,而是避免把大中间量(\(S, P\))写到 HBM。
9 实验结论与适用场景¶


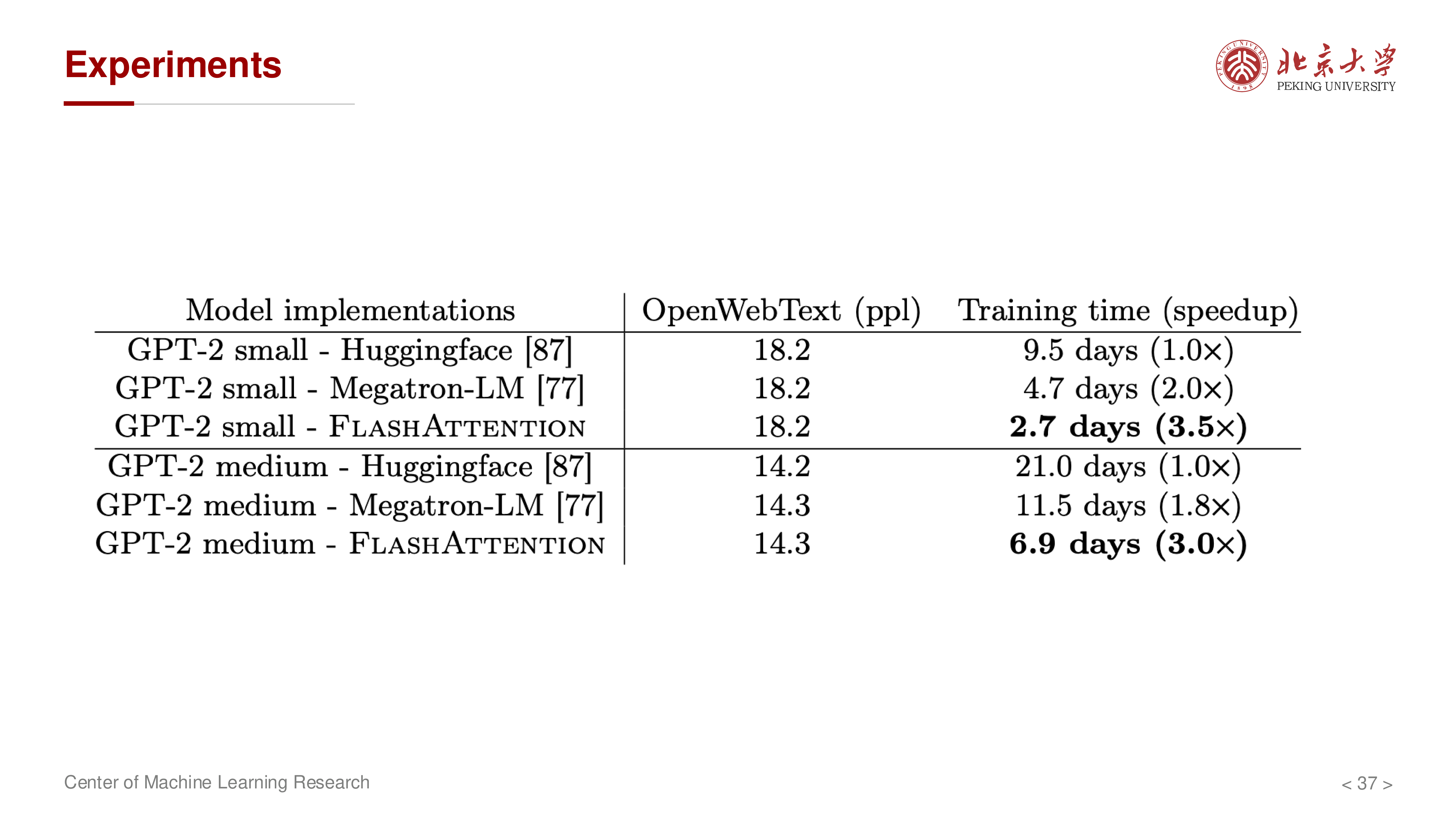
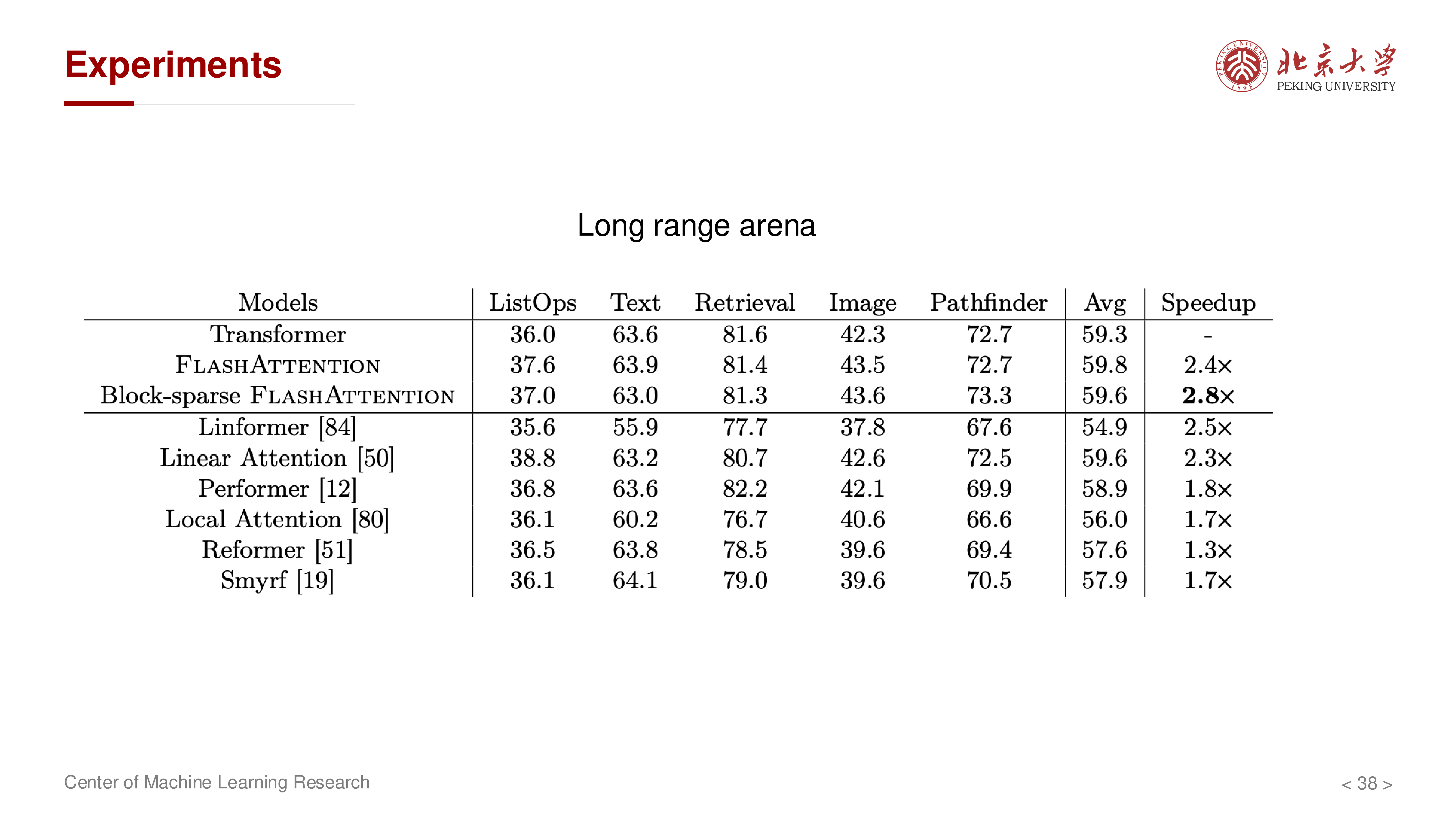
从讲义实验部分可读出的核心信息:
- 在 BERT 训练场景(8 张 A100,目标精度 72.0%)下,FlashAttention 能在保持精度的同时加速训练
- 在长序列任务(Long Range Arena)上收益更明显
- 序列越长,IO 优化收益越大,这与前述 MAC/ HBM 分析一致
何时最值得用 FlashAttention
当模型受显存带宽约束、序列长度较长、注意力占总耗时比例较高时,FlashAttention 往往带来最明显收益。
10 与标准 Attention 的对照总结¶
| 维度 | 标准 Attention | FlashAttention |
|---|---|---|
| 数学定义 | 精确 softmax attention | 同样是精确 softmax attention |
| 执行方式 | 分阶段 kernel,中间量频繁落 HBM | kernel fusion + tiled execution |
| 是否存储完整 \(S,P\) | 通常需要 | 不需要 |
| 额外维护量 | 无 | 每行/每块维护 \(m,\ell,O\) |
| HBM 流量 | 高,含明显 \(N^2\) 项 | 显著下降,受片上块复用影响 |
| 长序列扩展性 | 差 | 明显更好 |
11 逐页索引(覆盖 1-39 页)¶
为确保与原讲义逐页对应,下面给出页号与本文位置映射:
- p1:课程标题与讲者信息(见第 1 节首图)
- p2-p5:自注意力回顾与示意(见第 1 节)
- p6:FLOPs 与二次复杂度(见第 1、2 节)
- p7:GPU 内存层次与 IO 模型(见第 2 节)
- p8-p9:标准实现 MAC 分解、memory-bound 讨论(见第 2 节)
- p10-p11:FlashAttention 引入与 Kernel Fusion(见第 3 节)
- p12-p20:无 softmax 简化推导与 HBM 对比(见第 4 节)
- p21:Online Softmax(见第 5 节)
- p22-p24:分块 softmax 合并公式与“只存 m,l,O”(见第 6 节)
- p25-p32:固定 K/V、遍历 Q 的块执行过程(见第 7 节)
- p33-p34:HBM 成本与显存结论(见第 8 节)
- p35:算法总览(见第 8、9 节)
- p36-p38:实验与长序列评估(见第 9 节)
- p39:致谢页
12 参考¶
- Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, Christopher Re, FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness, NeurIPS 2022.
- Kun Yuan, Center for Machine Learning Research @ PKU, FlashAttention 课程讲义(
22_FlashAttention.pdf)。