基础数据结构(离散化、堆、树状数组)
目录¶
- 离散化
- 堆与优先队列
- 树状数组
1 离散化¶
离散化是一种数据处理的技巧,本质上可以看作是一种哈希,其保证数据结构在哈希以后仍然保持原来的状态。
- 创建原数组的副本。
- 将副本中的值从小到大排序。
- 将排序好的副本去重。
- 查找原数组的每一个元素在副本中的位置,位置即为排名,将其作为离散化后的值。
// arr[i] 为初始数组,下标范围为 [1, n]
for (int i = 1; i <= n; ++i) // step 1
tmp[i] = arr[i];
std::sort(tmp + 1, tmp + n + 1); // step 2
int len = std::unique(tmp + 1, tmp + n + 1) - (tmp + 1); // step 3
for (int i = 1; i <= n; ++i) // step 4
arr[i] = std::lower_bound(tmp + 1, tmp + len + 1, arr[i]) - tmp;
2 堆与优先队列¶
堆是一棵树,其每个节点都有一个键值,且每个节点的键值都大于等于/小于等于其父亲的键值。
每个节点的键值都大于等于其父亲键值的堆叫做小根堆,否则叫做大根堆。STL 中的 priority_queue 其实就是一个大根堆。(priority_queue<int, vector<int>, greater<int>> 是一个小根堆。)
(小根)堆主要支持的操作有:插入一个数、查询最小值、删除最小值、合并两个堆、减小一个元素的值。
一些功能强大的堆(可并堆)还能(高效地)支持 merge 等操作。
一些功能更强大的堆还支持可持久化,也就是对任意历史版本进行查询或者操作,产生新的版本。
习惯上,不加限定提到「堆」时往往都指二叉堆。
2.1 建堆¶
自底向上逐步把子树调整成堆,注意保持子树性质。
向上调整:
void up(int x) {
while (x > 1 && h[x] > h[x / 2]) {
swap(h[x], h[x / 2]);
x /= 2;
}
}
向下调整:
void down(int x) {
while (x * 2 <= n) {
int t = x * 2;
if (t + 1 <= n && h[t + 1] > h[t]) t++;
if (h[t] <= h[x]) break;
swap(h[x], h[t]);
x = t;
}
}
方法一:使用 decreasekey(向上调整),从根节点开始,按 BFS 序进行。
void build_heap_1() {
for (i = 1; i <= n; i++) up(i);
}
复杂度 \(O(n\log n)\)
方法二:使用向下调整。
void build_heap_2() {
for (i = n; i >= 1; i--) down(i);
}
每次合并两个已经调整好的堆。复杂度 \(O(n)\)
3 树状数组¶
3.1 引入¶
树状数组是一种支持 单点修改 和 区间查询 的,代码量小的数据结构。
什么是「单点修改」和「区间查询」?
假设有这样一道题:
已知一个数列 a,你需要进行下面两种操作:
- 给定
x, y将a[x]自增y。 - 给定
l, r,求解a[l...r]的和。
其中第一种操作就是「单点修改」,第二种操作就是「区间查询」。 类似地还有:「区间修改」、「单点查询」。它们分别的一个例子如下:
- 区间修改:给定 \(l, r, x\),将 \(a\) 中的每个数都分别自增 \(x\);
- 单点查询:给定 \(x\),求解 \(a\) 的值。
注意到,区间问题一般严格强于单点问题,因为对单点的操作相当于对一个长度为 1 的区间操作。
普通树状数组维护的信息及运算要满足 结合律 且 可差分,如加法(和)、乘法(积)、异或等。
- 可差分:具有逆运算的运算,即已知 \(x \circ y\) 和 \(x\) 可以求出 \(y\)。
需要注意的是:
- 模意义下的乘法若要可差分,需保证每个数都存在逆元(模数为质数时一定存在);
- 例如 \(\gcd, \max\) 这些信息不可差分,所以不能用普通树状数组处理,但是:
- 使用两个树状数组可以用于处理区间最值,见 Efficient Range Minimum Queries using Binary Indexed Trees。
- 一种支持不可差分信息查询的,\(\Theta(\log^2n)\) 时间复杂度的拓展树状数组。
事实上,树状数组能解决的问题是线段树能解决的问题的子集:树状数组能做的,线段树一定能做;线段树能做的,树状数组不一定可以。然而,树状数组的代码要远比线段树短,时间效率常数也更小,因此仍有学习价值。
有时,在 差分数组 和 辅助数组 的帮助下,树状数组还可解决更强的 区间加单点值 和 区间加区间和 问题。
3.2 基本原理¶
树状数组可以快速求解信息的原因:我们总能将一段前缀 [1, n] 拆成 不多于 \(\log n\) 段区间,使得这 \(\log n\) 段区间的信息是 已知的。
于是,我们只需要合并这 \(\log n\) 段区间的信息,就可以得到答案。
不难发现信息必须满足结合律。
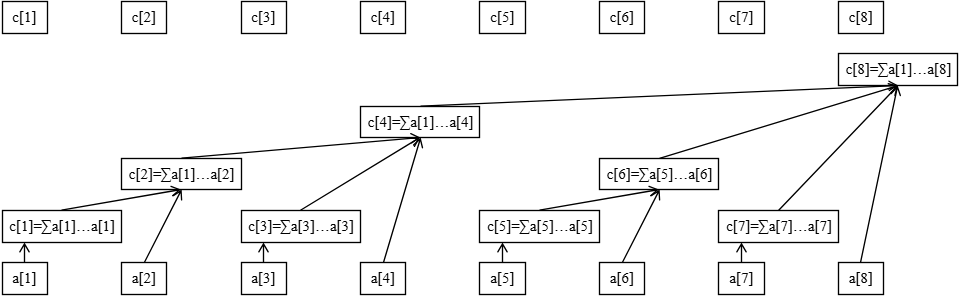
树状数组的工作原理:

最下面的八个方块代表原始数据数组 \(a\)。上面参差不齐的方块代表数组 \(a\) 的上级—— \(c\) 数组。
\(c\) 数组就是用来存储原始数组 \(a\) 某段区间的和,也就是说,这些区间的信息是已知的,我们的目标就是把查询拆成这些小区间。
例如,从图中可以看出:
- \(c_2\) 管辖的是 \(a[1 \dots 2]\)
- \(c_4\) 管辖的是 \(a[1 \dots 4]\)
- \(c_6\) 管辖的是 \(a[6 \dots 6]\)
- \(c_8\) 管辖的是 \(a[1 \dots 8]\)
- 剩下的 \(c[x]\) 管辖的都是 \(a[x]\) 自己(可以看做 \(a[x \dots x]\) 的长度为 \(1\) 的小区间)
不难发现,\(c[x]\) 管辖的一定是一段右边界是 \(x\) 的区间总信息。先不管左边界,先来感受一下树状数组是如何查询的。
举例:计算 \(a[1\dots7]\) 的和。
过程:从 \(c_7\) 开始往前跳,发现 \(c_7\) 只管辖 \(a_7\) 这一个元素;然后找 \(c_6\),发现 \(c_6\) 管辖的是 \(a[6 \dots 6]\),然后跳到 \(c_4\),发现 \(c_4\) 管辖的是 \(a[1\dots4]\) 这些元素,然后再试图跳到 \(c_0\),但事实上 \(c_0\) 不存在,不跳了。
我们刚刚找到的 \(c\) 是 \(c_7, c_6, c_4\),这就是 \(a[1\dots7]\) 拆分出的三个小区间,合并得到答案是 \(c_7 + c_6 + c_4\)。
举例:计算 \(a[4\dots7]\) 的和。
我们还是从 \(c_7\) 开始跳,跳到 \(c_6\) 再跳到 \(c_4\)。此时我们发现它管理了 \(a[1\dots4]\) 的和,但是我们不想要 \(a[1\dots3]\) 这一部分,怎么办呢?很简单,减去 \(a[1\dots3]\) 的和就行了。
那不妨考虑最开始,就将查询 \(a[4\dots7]\) 的和转化为查询 \(a[1\dots7]\) 的和,以及查询 \(a[1\dots3]\) 的和,最终将两个结果作差。
3.3 管辖区间¶
树状数组中规定,\(c[x]\) 管辖的区间长度为 \(2^k\),其中:
- 设二进制最低位为第 \(0\) 位,则 \(k\) 恰好为 \(x\) 二进制表示中,最低位的
1所在的二进制位数; - \(2^k\) (\(c[x]\) 的管辖区间长度)恰好为 \(x\) 二进制表示中,最低位的
1以及后面所有的 \(0\) 组成的数。
我们记 \(x\) 二进制最低位 1 以及后面的 0 组成的数为 \(\text{lowbit}(x)\),那么 \(c[x]\) 管辖的区间就是 \([x - \text{lowbit}(x) + 1, x]\)。
根据 ICS 中的知识,可知 lowbit(x) = x & -x。
3.4 区间查询¶
回顾查询 \(a[1\dots7]\) 的过程,不难发现,每次往前跳,一定是跳到现区间的左端点的左一位,作为新区间的右端点,这样才能将前缀不重不漏地拆分。比如现在 \(c_6\) 管的是 \(a[5\dots6]\),下一次就跳到 \(5 - 1 = 4\),即访问 \(c_4\)。
我们可以写出查询 \(a[1 \dots x]\) 的过程:
- 从 \(c[x]\) 开始往前跳,有 \(c[x]\) 管辖 \(a[x - \text{lowbit}(x) + 1 \dots x]\)
- 令 \(x \leftarrow x - \text{lowbit}(x)\),如果 \(x = 0\) 说明已经跳到尽头了,终止循环;否则回到第一步。
- 将跳到的 \(c\) 合并。
实现时,我们不一定要先把 \(c\) 都跳出来然后一起合并,可以边跳边合并。
比如我们要维护的信息是和,直接令初始 \(ans = 0\),然后每跳到一个 \(c[x]\) 就 \(ans \leftarrow ans + c[x]\),最终 \(ans\) 就是所有合并的结果。
int getsum(int x) {
int ans = 0;
while (x > 0) {
ans = ans + c[x];
x = x - lowbit(x);
}
return ans;
}
3.5 树状数组与其树形态的性质¶
在讲解单点修改之前,先讲解树状数组的一些基本性质,以及其树形态来源,这有助于更好理解树状数组的单点修改。
我们约定:
- \(l(x) = x - \text{lowbit}(x) + 1\),即 \(l(x)\) 是 \(c[x]\) 管辖范围的左端点。
- 对于任意正整数 \(x\),总能将 \(x\) 表示成 \(s \times 2^{k + 1} + 2^k\) 的形式,其中 \(\text{lowbit}(x) = 2^k\)。
- 下面 "\(c[x]\) 和 \(c[y]\) 不交" 指 \(c[x]\) 的管辖范围和 \(c[y]\) 的管辖范围不相交,即 \([l(x),x]\) 和 \([l(y),y]\) 不相交。"\(c[x]\) 包含于 \(c[y]\)" 等表述同理。
性质 1 :对于 \(x \leq y\),要么有 \(c[x]\) 和 \(c[y]\) 不交,要么有 \(c[x]\) 包含于 \(c[y]\)。
性质 2 :\(c[x]\) 真包含于 \(c[x + \text{lowbit}(x)]\)。
性质 3 :对于任意 \(x < y < x + \text{lowbit}(x)\),有 \(c[x]\) 和 \(c[y]\) 不交。
有了这三条性质的铺垫,我们接下来看树状数组的树形态(请忽略 \(a\) 向 \(c\) 的连边)。
事实上,树状数组的树形态是 \(x\) 向 \(x + \text{lowbit}(x)\) 连边得到的图,其中 \(x + \text{lowbit}(x)\) 是 \(x\) 的父亲。
注意,在考虑树状数组的树形态时,我们不考虑树状数组大小的影响,即我们认为这是一棵无限大的树,方便分析。实际实现时,我们只需用到 \(x \leq n\) 的 \(c[x]\),其中 \(n\) 是原数组的长度。
这棵树满足很多美好的性质,下面举例若干(设 \(fa[u]\) 表示 \(u\) 的直系父亲):
- \(u < fa[u]\)。
- \(u\) 大于任何一个 \(u\) 的后代,小于任何一个 \(u\) 的祖先。
- 点 \(u\) 的 \(\text{lowbit}\) 严格小于 \(fa[u]\) 的 \(\text{lowbit}\)。
- 点 \(x\) 的高度是 \(\log_2\text{lowbit}(x)\),即 \(x\) 二进制最低位
1的位数。 - \(c[u]\) 真包含于 \(c[v]\),其中 \(v\) 是 \(u\) 的任一祖先(性质 2 归纳)。
- 对于任意 \(v^{'} > u\),若 \(v^{'}\) 不是 \(u\) 的祖先,则 \(c[u]\) 和 \(c[v^{'}]\) 不交。
- 对于任意 \(v > u\),当且仅当 \(v\) 是 \(u\) 的祖先,\(c[u]\) 真包含于 \(c[v]\)(上面几条性质的总结, 树状数组单点修改的核心原理)。
- 设 \(u = s \times 2^{k + 1} + 2^k\),则其儿子数量为 \(k = \log_2\text{lowbit}(u)\),编号分别为 \(u - 2^t(0 \leq t < k)\)。
- 举例:假设 \(k = 3\),\(u\) 的二进制编号为
...1000,则 \(u\) 有三个儿子,二进制编号分别为...0111、...0110、...0100。
- 举例:假设 \(k = 3\),\(u\) 的二进制编号为
- \(u\) 的所有儿子对应 \(c\) 的管辖区间恰好拼接成 \([l(u), u - 1]\)。
3.6 单点修改¶
现在来考虑如何单点修改 \(a[x]\)。
我们的目的是快速正确地维护 \(c\) 数组。为保证效率,我们只需遍历并修改管辖了 \(a[x]\) 的所有 \(c[y]\),因为其他的 \(c\) 显然没有发生变化。
管辖 \(a[x]\) 的 \(c[y]\) 一定包含 \(c[x]\)(根据性质 1),所以 \(y\) 在树状数组树形态上是 \(x\) 的祖先。因此我们从 \(x\) 开始不断跳父亲,直到跳得超过了原数组长度为止。
设 \(n\) 表示 \(a\) 的大小,不难写出单点修改 \(a[x]\) 的过程:
- 初始令 \(x^{'} = x\)。
- 修改 \(c[x^{'}]\)。
- 令 \(x^{'} \leftarrow x^{'} + \text{lowbit}(x^{'})\),如果 \(x^{'} > n\) 说明已经跳到尽头了,终止循环;否则回到第二步。
区间信息和单点修改的种类,共同决定 \(c[x^{'}]\) 的修改方式。下面给出几个例子:
- 若 \(c[x^{'}]\) 维护区间和,修改种类是将 \(a[x]\) 加上 \(p\),则修改方式是将所有 \(c[x^{'}]\) 也加上 \(p\)。
- 若 \(c[x^{'}]\) 维护区间积,修改种类是将 \(a[x]\) 乘上 \(p\),则修改方式则是将所有 \(c[x^{'}]\) 也乘上 \(p\)。
然而,单点修改的自由性使得修改的种类和维护的信息不一定是同种运算,比如,若 \(c[x^{'}]\) 维护区间和,修改种类是将 \(a[x]\) 赋值为 \(p\),可以考虑转化为将 \(a[x]\) 加上 \(p - a[x]\)。如果是将 \(a[x]\) 乘上 \(p\),就考虑转化为 \(a[x]\) 加上 \(a[x] \times p - a[x]\)。
void add(int x, int k) {
while (x <= n) {
c[x] = c[x] + k;
x = x + lowbit(x);
}
}
3.7 建树¶
也就是根据最开始给出的序列,将树状数组建出来(\(c\) 全部预处理好)。
一般可以直接转化为 \(n\) 次单点修改,时间复杂度为 \(\Theta(n \log n)\)。
比如给定序列 \(a = (5, 1, 4)\) 要求建树,直接看作对 \(a[1]\) 单点加 \(5\),对 \(a[2]\) 单点加 \(1\),对 \(a[3]\) 单点加 \(4\) 即可。
也有 \(\Theta(n)\) 的建树方法。
方法一:每一个节点的值是由所有与自己直接相连的儿子的值求和得到的。因此可以倒着考虑贡献,即每次确定完儿子的值后,用自己的值更新自己的直接父亲。
// O(n) 建树
void init() {
for (int i = 1; i <= n; i++) {
t[i] += a[i];
int j = i + lowbit(i);
if (j <= n) t[j] += t[i];
}
}
方法二:前面讲到 \(c[i]\) 表示的区间是 \([i - \text{lowbit}(i) + 1, i]\),那么我们可以先预处理一个 \(sum\) 前缀和数组,再计算 \(c\) 数组。
// O(n) 建树
void init() {
for (int i = 1; i <= n; i++) {
t[i] = sum[i] - sum[i - lowbit(i)];
}
}
3.8 区间加区间和¶
这个问题可以使用两个树状数组维护差分数组解决。
考虑序列 \(a\) 的差分数组 \(d\),其中 \(d[i] = a[i] - a[i - 1]\)。由于差分数组的前缀和就是原数组,所以 \(a_i = \sum\limits_{j = 1}^i d_j\)。
一样地,我们考虑将查询区间和通过差分转化为查询前缀和。那么考虑查询 \(a[1 \dots r]\) 的和,即 \(\sum\limits_{i = 1}^r a_i\),进行推导:
要用两个树状数组分别维护 \(d_i\) 和 \(d_i \times i\) 的和信息。
考虑给原数组 \(a[l \dots r]\) 区间加 \(x\) 给 \(d\) 带来的影响。
差分是 \(d[i] = a[i] - a[i - 1]\);
- \(a[l]\) 多了 \(v\) 而 \(a[l - 1]\) 不变,所以 \(d[l]\) 的值多了 \(v\)
- \(a[r + 1]\) 不变而 \(a[r]\) 多了 \(v\),所以 \(d[r + 1]\) 的值少了 \(v\)
- 对于不等于 \(l\) 且不等于 \(r + 1\) 的其他任意 \(i\),\(a[i]\) 和 \(a[i - 1]\) 要么都没发生变化,要么都加了 \(v\),它们的差都没有变化,所以其他的 \(d[i]\) 都不变
所以维护方式为:对于维护 \(d_i\) 的树状数组,对 \(l\) 单点加 \(v\),\(r + 1\) 单点加 \(-v\);对于维护 \(d_i \times i\) 的树状数组,对 \(l\) 单点加 \(v \times l\),对 \(r + 1\) 单点加 \(-v \times (r + 1)\)。
而更弱的问题,"区间加求单点值",只需用树状数组维护一个差分数组 \(d_i\)。询问 \(a[x]\) 的单点值,直接求 \(d[1 \dots x]\) 的和即可。
这里直接给出"区间加区间和"的代码:
int t1[MAXN], t2[MAXN], n;
int lowbit(int x) { return x & -x; }
void add(int k, int v) {
int v1 = k * v;
while (k <= n) {
t1[k] += v, t2[k] += v1;
// 注意不能写成 t2[k] += k * v,因为 k 的值已经不是原数组的下标了
k += lowbit(k);
}
}
int getsum(int *t, int k) {
int ret = 0;
while (k) {
ret += t[k];
k -= lowbit(k);
}
return ret;
}
void add1(int l, int r, int v) {
add(l, v), add(r + 1, -v); // 将区间加差分为两个前缀加
}
long long getsum1(int l, int r) {
return (r + 1ll) * getsum(t1, r) - 1ll * l * getsum(t1, l - 1)
- (getsum(t2, r) - getsum(t2, l - 1));
}
根据这个原理,应该可以实现"区间乘区间积","区间异或一个数,求区间异或值"等,只要满足维护的信息和区间操作是同种运算即可。
3.9 权值树状数组及应用¶
我们知道,普通树状数组直接在原序列的基础上构建,\(c_6\) 表示的就是 \(a[5 \dots 6]\) 的区间信息。
然而事实上,我们还可以在原序列的权值数组上构建树状数组,这就是权值树状数组。
什么是权值数组?
一个序列 \(a\) 的权值数组 \(b\),满足 \(b[x]\) 的值为 \(x\) 在 \(a\) 中的出现次数。 例如:\(a = (1,3,4,3,4)\) 的权值数组为 \(b = (1,0,2,2)\)。 很明显,\(b\) 的大小和 \(a\) 的值域有关。 若原数组值域过大,且重要的不是具体值而是值与值之间的相对大小关系,常常离散化原数组后再建立权值数组。 另外,权值数组是原数组无序性的一种表示:它重点描述数组的元素内容,忽略了数组的顺序,若两数组只是顺序不同,所含内容一致,则它们的权值数组相同。 因此,对于给定数组的顺序不影响答案的问题,在权值数组的基础上思考一般更直观。
运用权值树状数组,我们可以解决一些经典问题。
3.9.1 单点修改,查询全局第 k 小¶
在此处只讨论第 \(k\) 小,第 \(k\) 大问题可以通过简单计算转化为第 \(k\) 小问题。
该问题可离散化,如果原序列 \(a\) 值域过大,离散化后再建立权值数组 \(b\)。注意,还要把单点修改中涉及到的值也一起离散化,不能只离散化原数组 \(a\) 中的元素。
对于单点修改,只需将原数列的单点修改转化为对权值数组的单点修改即可。具体来说,原数组 \(a[x]\) 从 \(y\) 修改为 \(z\),转化为对权值数组 \(b\) 的单点修改就是 \(b[y]\) 单点减 \(1\),\(b[z]\) 单点加 \(1\)。
对于查询第 \(k\) 小,考虑二分 \(x\),查询权值数组中 \([1,x]\) 的前缀和,找到 \(x_0\) 使得 \([1, x_0]\) 的前缀和 \(< k\) 而 \([1, x_0 + 1]\) 的前缀和 \(\geq k\),则第 \(k\) 大的数是 \(x_0 + 1\)(注:这里认为 \([1,0]\) 的前缀和是 \(0\))。
这样做的时间复杂度是 \(\Theta(\log^2n)\) 的。
考虑用倍增替代二分。
设 \(x=0, sum = 0\),枚举 \(i\) 从 \(\log_2 n\) 降为 \(0\):
- 查询权值数组中 \([x + 1 \dots x + 2^i]\) 的区间和 \(t\)
- 如果 \(sum + t < k\),拓展成功,\(x \leftarrow x + 2^i\),\(sum \leftarrow sum + t\);否则拓展失败,不操作
这样得到的 \(x\) 是满足 \([1 \dots x]\) 前缀和 \(< k\) 的最大值,所以最终 \(x + 1\) 就是答案。
看起来这种方法时间效率上没有任何改善,但事实上,查询 \([x + 1 \dots x + 2^i]\) 的区间和只需要访问 \(c[x + 2^i]\) 的值即可。
原因很简单,考虑 \(\text{lowbit}(x + 2^i)\),它一定是 \(2^i\),因为 \(x\) 之前只累加过 \(2^j\) 满足 \(j > i\)。因此 \(c[x + 2^i]\) 表示的区间就是 \([x + 1 \dots x + 2^i]\)。
如此一来,时间复杂度就降低为 \(\Theta(\log n)\)。
// 权值树状数组查询第 k 小
int kth(int k) {
int sum = 0, x = 0;
for (int i = log2(n); ~i; --i) {
x += 1 << i; // 尝试扩展
if (x >= n || sum + t[x] >= k) // 如果拓展失败
x -= 1 << i;
else
sum += t[x];
}
return x + 1;
}
3.9.2 全局逆序对(全局二维偏序)¶
全局逆序对也可以用权值树状数组巧妙解决。
该问题可离散化。
我们考虑从 \(n\) 到 \(1\) 倒序枚举 \(i\),作为逆序对中第一个元素的索引,然后计算有多少个 \(j > i\) 满足 \(a[j] < a[i]\),然后累计答案即可。
事实上,我们只需要这样做(设当前 \(a[i] = x\)):
- 查询 \(b[1 \dots x - 1]\) 的前缀和,即为左端点为 \(a[i]\) 的逆序对的数量。
- \(b[x]\) 自增 \(1\)。
原因十分自然:出现在 \(b[1 \dots x - 1]\) 中的元素一定比当前的 \(x = a[i]\) 小,而 \(i\) 的倒序枚举,自然使得这些已在权值数组中的元素,在原数组上的索引 \(j\) 大于当前遍历到的索引 \(i\)。
3.10 时间戳优化¶
对付多组数据很常见的技巧。若每次输入新数据都暴力清空树状数组,就可能会造成超时。因此用 \(tag\) 标记,存储当前节点上次使用的时间(即最近一次是被第几组数据使用)。每次操作时判断这个位置 \(tag\) 中的时间和当前时间是否相同,就可以判断这个位置是 \(0\) 还是数组内的值。
int tag[MAXN], t[MAXN], Tag;
void reset() { ++Tag; }
void add(int k, int v) {
while (k <= n) {
if (tag[k] != Tag) t[k] = 0;
t[k] += v, tag[k] = Tag;
k += lowbit(k);
}
}
int getsum(int k) {
int ret = 0;
while (k) {
if (tag[k] == Tag) ret += t[k];
k -= lowbit(k);
}
return ret;
}
总结¶
| 数据结构 | 核心操作 | 时间复杂度 | 适用场景 |
|---|---|---|---|
| 离散化 | 坐标压缩 | \(O(n\log n)\) | 值域过大时 |
| 堆 | 插入、删除、查询最值 | \(O(\log n)\) | 优先队列场景 |
| 树状数组 | 单点修改、区间查询 | \(O(\log n)\) | 区间统计问题 |